
Using masked language modeling as a way to detect literary clichés. Training BERT to use on North Korean language data. Borrowing a pseudo-perplexity metric to use as a measure of literary creativity. Experimenting with the metric on sentences sampled from different North Korean sources.
0. Introduction
1. Language models, perplexity & BERT
2. Training a North Korean BERT
3. Predicting North Korean poetry
0. Introduction
A few weeks ago, I came across a blog post entitled “How predictable is fiction?”. The author, Ted Underwood, attempts to measure the predictability of a narrative by relying on BERT’s next sentence prediction capabilities. Novels from genres that traditionally rely more heavily on plot conventions such as thriller or crime should be more predictable than more creative genres with unpredictable (to the reader and the model) plotlines – at least in theory.
The idea got me thinking that it might be possible to develop a similar measure for the predictability of writing style by relying on another task BERT can be trained on, masked language modeling. In lay language, masked language modeling can be described as a fill-in-the-blanks task. A model is given a sentence, a token in the sentence is hidden (replaced by a token like [MASK]) and the model made to predict it using the surrounding context words. The idea is that we can use the probabilities generated by such a model to assess how predictable the style of a sentence is. For instance, in the following English language sentence:
His hair as gold as the sun , his eyes blue like the [MASK].
BERT (trained on English language data) can predict sky with a 27% probability. But in this sentence:
The [MASK] above the port was the color of television, tuned to a dead channel
the probability of sky falls much lower, with BERT instead giving tokens such as screen, window or panel the highest probabilities – since the comparison to television makes the presence of the word less predictable. The probabilities returned by BERT line up with what we typically associate with literary originality or creativity. It can assess the “preciosity” of a word: given two synonyms, the rarer one will receive a lower probability. A low probability can also reflect the unexpectedness of the type of comparisons used in literary or poetic language. We might say, in structuralist terms, that BERT’s probabilities are computed following paradigmatic (predicting a word over others) and syntagmatic (based on its context) axes, whose order the “poetic function” of language subverts. By aggregating word probabilities within a sentence, we could then see how “fresh” or unexpected its language is.
The intuition, therefore, is that BERT would be better at predicting boilerplate than original writing. To test this out, I figured I would try it on a corpus where clichés are definitely common: North Korean literature.
1. Language models, perplexity & BERT
The idea that a language model can be used to assert how “common” the style of sentence is not new. The most widely used metric used to evaluate language models, perplexity, can be used to score how probable (i.e. how meaningful and grammatically well-formed) a sequence of words (i.e. a sentence) is. Perplexity scores are used in tasks such as automatic translation or speech recognition to rate which of different possible outputs are the most likely to be a well-formed, meaningful sentence in a particular target language. There are however a few differences between traditional language models and BERT.
Traditional language models are sequential, working from left to right. You can think of it as an auto-complete feature: with the knowledge of the first words of a sentence, what is the most probable word that will come next. Some models have attempted to bypass this left-to-right limitation by using a shallow form of bidirectionality and using both the left-to-right and right-to-left contexts. But the left-to-right context and right-to-left context nonetheless remain independent from one another.
This is in contrast with BERT’s bidirectionality in which each word depends on the all the other words in the sentence. This deep bi-directionality is a strong advantage, especially if we are interested in literature, since it is much closer to how a human reader would assert the unexpectedness of a single word within a sentence. But the fact that BERT differs from traditional language models (although it is nonetheless a language model) also means that the traditional way of computing perplexity via the chain rule does not work. But that does not mean that obtaining a similar metric is impossible.
Wang et al. (2020) simply take the geometric mean of the probability of each word in the sentence:

which can constitute a convenient heuristic for approximating perplexity. Building on Wang & Cho (2019)‘s pseudo-loglikelihood scores, Salazar et al. (2020) devise a pseudo-perplexity score for masked language models defined as:

which we’ll use as our scoring metric.
2. Training a North Korean BERT
Having a metric is nice, but it won’t be much use if we don’t have a model. Even though Korean was recently found to be on the upper half of the NLP divide between low- and high-resource languages, that is really only true of South Korea. While North and South Korean language remain syntactically and lexically fairly similar, but cultural differences between the two means that language models trained on one are unlikely to perform well on the other (see this previous post for a quick overview of how embeddings trained in each of the languages can differ). And while there are a couple BERT-based models trained on South Korean data. There are, less surprisingly, no models trained on North Korean data.
Training BERT requires a significant amount of data. I do have quite a lot of good quality full-text North Korean data (mostly newspapers and literature), but even that only amounts to a 1.5Gb corpus of 4.5 million sentences and 200 million tokens. Some have successfully trained BERT from scratch with hardly more data, so the corpus might have been enough to do that. But since there were existing resources for the South Korean language and the two languages share a number of similarity, I figured I might be better off by simply grabbing one of the South Korean models and fine-tuning it on my North Korean corpus. I went with KoBERT, which is available as a huggingface model and would be easy to fine-tune.
This approach still presents a couple of challenges. There are significant spelling differences between North and South, so the vocabulary of the original model’s tokenizer won’t work well. This was compounded by a second problem, this time specific to the task at hand. I wanted to retain a high level of control over the tokens that would be masked in order to play around with the model and test masking different kinds of words. However, BERT tokenizers usually use Byte-Pair Encoding or Wordpiece which breaks down tokens into smaller sub units. This is a powerful way to handle out-of-vocabulary tokens as well as prefixes and suffixes. However, that isn’t very helpful for us because instead of masking a single word, we would have to mask the word’s subunits and then find a way to meaningfully aggregate the probabilities of said subunits – a process which can be tricky.
My solution is certainly not very subtle. I added a first layer of tokenization (by morpheme) then trained a new BERT Tokenizer on the tokenized corpus with a large vocabulary to be able to at least handle a good number of common words:
from pathlib import Path
from tokenizers import BertWordPieceTokenizer
paths = [str(x) for x in Path("data/").glob("*.txt")]
tokenizer = BertWordPieceTokenizer(
vocab_file=None,
clean_text=True,
handle_chinese_chars=True,
strip_accents=False,
lowercase=False,
wordpieces_prefix="##")
min_frequency = 5
vocab_size = 32000
limit_alphabet= 6000
tokenizer.train(files=paths, vocab_size=vocab_size, min_frequency=5, special_tokens=['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[MASK]'])
tokenizer.train(
files=paths,
vocab_size=vocab_size,
min_frequency=min_frequency,
show_progress=True,
limit_alphabet=limit_alphabet,
special_tokens=['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[MASK]',
'[BOS]', '[EOS]', '[UNK0]', '[UNK1]', '[UNK2]', '[UNK3]', '[UNK4]', '[UNK5]', '[UNK6]', '[UNK7]', '[UNK8]', '[UNK9]',
'[unused0]', '[unused1]', '[unused2]', '[unused3]', '[unused4]', '[unused5]', '[unused6]', '[unused7]', '[unused8]', '[unused9]',
]
)
tokenizer.save(".", "nkbert")
Then I simply added the vocabulary generated by the tokenizer to KoBERT’s tokenizer. One issue I encountered at this point was that adding any more than a few vocabulary words to an existing tokenizer’s vocabulary with huggingface’s tokenizers and the add_token() function will create a bottleneck that will make the finetuning process EXTREMELY slow. You will spend more time loading the tokenizer than actually fine-tuning the model. Fortunately a good soul had ran into the issue and solved it with the following workaround, which you can easily incorporate into huggingface’s sample training script:
from collections import OrderedDict
from transformers import BertTokenizer, WordpieceTokenizer
with open('nkbert-vocab.txt', 'r', encoding='utf8') as fp:
vocab = fp.read().splitlines()
tokens_to_add = [token for token in vocab if not (token in tokenizer.vocab or token in tokenizer.all_special_tokens)]
tokenizer.vocab = OrderedDict([
*tokenizer.vocab.items(),
*[
(token, i + len(tokenizer.vocab))
for i, token in enumerate(tokens_to_add)
]
])
tokenizer.ids_to_tokens = OrderedDict([(ids, tok) for tok, ids in tokenizer.vocab.items()])
tokenizer.wordpiece_tokenizer = WordpieceTokenizer(vocab=tokenizer.vocab, unk_token=tokenizer.unk_token)
I then finetuned the original KoBERT solely on a masked language modeling task for a couple of epochs on a GPU equipped computer which took a couple of days. After that I was able to run a few test to ensure that the model ran well. To take a single example, let’s use the sentence “어버이수령 김일성동지께서는 이 회의에서 다음과 같이 교시하시였다.” (During this meeting the fatherly Leader Comrade Kim Il Sung taught us the following), a classic sentence you will find, with minor variations, at the beginning of a large number of publications in the DPRK. If we hide the token ‘김일성’ (Kim Il Sung), we can see how well the model does at predicting it:
[{‘sequence’: ‘[CLS] 어버이 수령 김일성 동지 께서 는 이 회의 에서 다음 과 같이 교시 하시 이 었 다. [SEP]’,
‘score’: 0.9850603938102722,
‘token’: 14754,
‘token_str’: ‘김일성’},
{‘sequence’: ‘[CLS] 어버이 수령 님 동지 께서 는 이 회의 에서 다음 과 같이 교시 하시 이 었 다. [SEP]’,
‘score’: 0.005277935415506363,
‘token’: 5778,
‘token_str’: ‘님’},
{‘sequence’: ‘[CLS] 어버이 수령 김정일 동지 께서 는 이 회의 에서 다음 과 같이 교시 하시 이 었 다. [SEP]’,
‘score’: 0.0029645042959600687,
‘token’: 14743,
‘token_str’: ‘김정일’},
{‘sequence’: ‘[CLS] 어버이 수령 김정숙 동지 께서 는 이 회의 에서 다음 과 같이 교시 하시 이 었 다. [SEP]’,
‘score’: 0.002102635568007827,
‘token’: 15209,
‘token_str’: ‘김정숙’}]
The most probable word is indeed Kim Il Sung, with 98% probability, the next one is the honorific suffix ‘님’ which makes sense as the word ‘수령님’ could also be used here, then comes Kim Jong Il and Kim Jong Suk (Kim Il Sung’s wife and Kim Jong Il’s mother). Both Kim Jong Il and Kim Jong Suk are possible, sensible substitutions but the title 어버이 수령 is much more commonly associated with Kim Il Sung, something reflected in the difference between each token’s probabilities.
Reassured that the model had learned enough to fill in the name of the Great Leader, I moved on to try it on a toy corpus.
3. Predicting North Korean poetry
To try out our literary predictability metric, I sampled sentences from 3 different sources. The Korean Central News agency, Poetry anthologies and about 100 different novels. None of these sources was included in the model’s training corpus of course. However, half of the training corpus consisted of Rodong Sinmun articles, the DPRK’s main newspaper, so the model would certainly be familiar with journalistic discourse. And about 30% came from literary sources, mostly literary magazines, including a bit (but proportionally not much) of poetry.
I started with a small sample of 500 sentences, which turned out to be enough to yield statistically significant results. I applied the pseudo-perplexity score given above, although I did introduce a significant modification. Korean has a lot of “easy to predict” grammatical particles or structures. For example, when using the form “을/ㄹ 수 있다”, it’s very easy to predict either ‘수’ or ‘있다’ given the two other words. Furthermore, Korean can mark the object of a verb with a specific particle (를/을). Predicting this particle being present between a noun and a verb is not hard. However, case particles can and are often omitted depending on context and individual preferences. Including it in the scoring of a sentence might therefore introduce bias, ranking writers who use it extensively as less creative than writers who use it more sparingly. To avoid this issue, I only masked nouns, verbs and adjectives (all words were still being used as context for the prediction of the masked token though). This also seems to make sense given our task, since we are more interested in predicting literary creativity than grammatical correctness.
The results, plotted as boxplots are as follow:
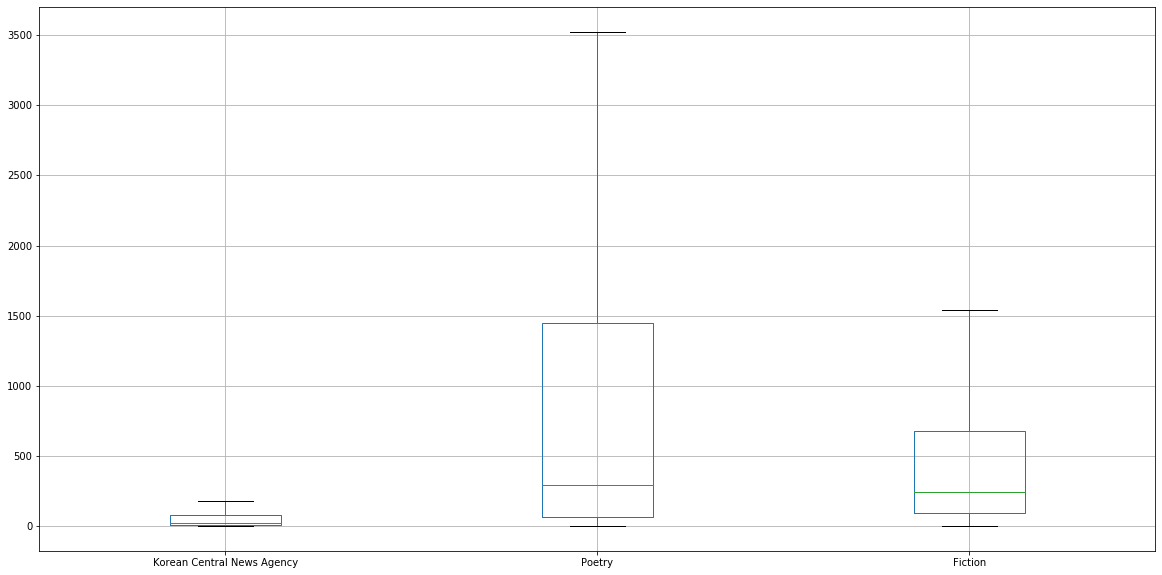
| Korean Central News Agency | Poetry | Fiction | |
|---|---|---|---|
| count | 500.00000 | 500.00000 | 500.00000 |
| mean | 107.17284 | 2763.12852 | 695.53613 |
| std | 429.92459 | 10193.23875 | 2702.78047 |
| min | 1.38257 | 1.39690 | 1.41605 |
| 25% | 8.24915 | 63.01481 | 97.27057 |
| 50% | 23.81456 | 291.19931 | 241.60294 |
| 75% | 78.56058 | 1447.97320 | 677.68299 |
| max | 8480.83891 | 155184.30224 | 56007.44665 |
Press releases from the Korean Central News Agency appear to be very predictable, which is understandable as many “stock sentences” are re-used from one article to the next. Just like Western media, North Korean media also has its share of evergreen content, with very similar articles being republished almost verbatim at a few years’ interval.
We can see that literary fiction appears a lot more unpredictable than journalism, but with nonetheless a good amount of predictable clichés. Poetry is on average much less predictable, which we might have expected. However, it is interesting to note that the median for the poetry corpus is roughly the same as that of the fiction corpus. This indicates that highly unpredictable, creative poetic verses are increasing the mean, but that a fair amount of poetry remain trite, predictable verse. We can see some examples of those poetic clichés by looking at the top 10 verses that received the lowest perplexity scores:
| rank | Korean | English |
|---|---|---|
| 1 | 위대한 장군님 | Great general |
| 2 | 조선로동당 위원장으로 높이 모시고 | Highly worshipping the Chairman of the Workers’ Party |
| 3 | 하나로 굳게 뭉쳐 우리 민족끼리 | Strongly united as one, among our nation |
| 4 | 얼마나 좋은가 | How good |
| 5 | 어버이수령님 경애하는 장군님 | Fatherly leader, respected General |
| 6 | 우리의 최고사령관동지! | Our comrade the highest leader! |
| 7 | 이 나라 인민이 온넋으로 추켜든 | This country’s people raising with their whole soul |
| 8 | 더 큰 기쁨과 환희로 터져오르리라 | Will burst open in even greater joy and delight |
| 9 | 장군님 평양으로 오실 때까지 | Until the General comes to Pyongyang |
| 10 | 우리의 령도자 김정일동지! | Our Leader Comrade Kim Jong Il! |
The majority of these are common ways to refer to the Kim family members and their various titles, however we do find a couple of more literary images among the lot such as number 7 and 8. At first glance, the metric seems to be effective at measuring literary conformism, and could potentially be used to perform “cliché extraction” in literary texts. Although maybe the high amount of political slogans and stock phrases about the Leader in North Korean discourse (across all discursive genres) make it a particularly good target for this kind of experiment. It would certainly be nice to have some more comparison points from other languages and literatures.