
With the goal of performing OCR and indexing the content of archival documents, this posts explains how to build a simple Python web scraper to extract data from a public website in order to process it locally.
1. Getting the Data
An important source of data for North Korean scholars is the Captured North Korean Documents collection, part of RG-242 record group of the United States’ National Archives. The collection is made up of several hundred thousands documents, from personal letters to wartime propaganda pictures or literary journals, which were published between 1945 and 1953 and later captured by U.S. troops during the Korean War. The physical documents are all stored in College Park, MD, making them hard and expensive to access for researchers outside of the East Coast.
Starting in 2004, the National Library of Korea (국립중앙도서관) sent collecting teams to the American Archives in order to collect scans of all record groups containing materials pertaining to Korea (more on this process later). The resulting scans were later made available on the library’s website. Unlike other North Korean materials kept in South Korea, access is free, unrestricted and available to all of the website’s visitors regardless of their region of origin.
This digital collection holds a large number of newspapers and magazines, but unfortunately our ability to search through them is fairly limited. Even if some indexes are available as metadata, search is limited to the publication’s names and/or authors. Unlike the Naver News Archive, the content of the publication is not searchable.
To make the processing of this data a little bit easier and faster for researchers, the following posts will attempt to perform OCR on these scans. The goal will not be to achieve a perfect transcript, but to extract individual articles from publications and a limited number of relevant tags for each. In order to make the database more searchable.
Getting the data might at first seem like a fairly straightforward process. Go the Korean National Library’s website, select the small “자세검색” (Detailed Search) blue button on top of the homepage’s searchbar (note that the option is only available for the Korean language homepage). Then, on the window that pops up select “해외수집기록물” (Archive materials collected overseas), enter what you are looking for and search. Each search result will then have a “원문 보기” (View original manuscript online) that lets you browse the document.
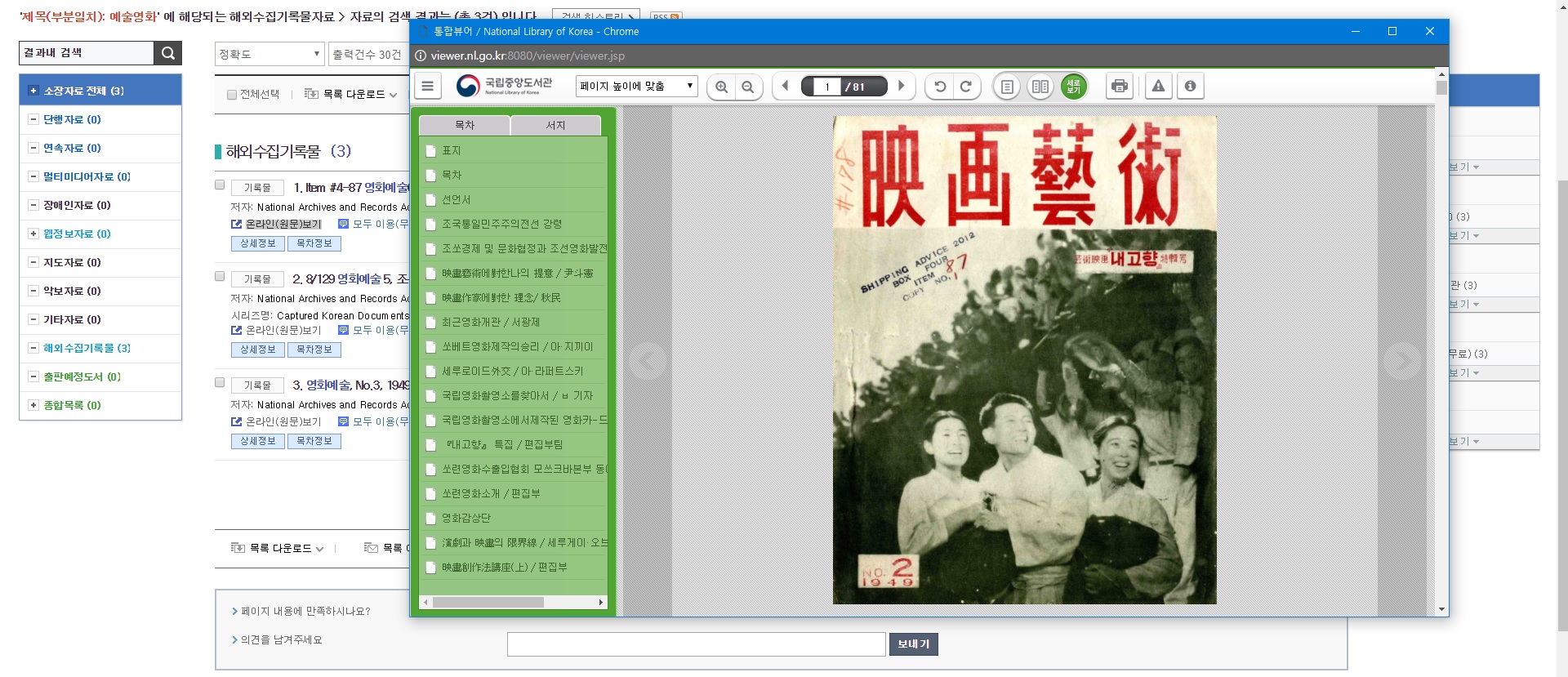
The problem is that the site’s viewer was designed to display copyrighted materials only accessible through the library’s network and to charge royalties for reproduction. (On the other hand, North Korea’s copyright law, first enacted in 2001, has a fairly wide definition of fair use. Scammed reproductions themselves are not protected by copyright.). Access to the data is therefore very limited. There are no options to print the pages or save them locally, and both right-click and the print-screen touch are disabled. Unfortunately, without being able to get a local copy, we won’t be able to do much with it.
Fortunately a quick look at the “Network” section of the Developer Tools Console in Chrome tells us that the viewer’s pages are created dynamically with JSP. Each page can be loaded separately to display a JPEG picture that can then be saved locally. Visiting each individual page and downloading the picture by hand would take an unnecessarily large amount of time, when we could quickly put together a scraper in Python that would do the work for us. Judging from the structure of the individual pages’ URLs that are listed in the console, all we need to access an individual page is the document’s ID and the page number.
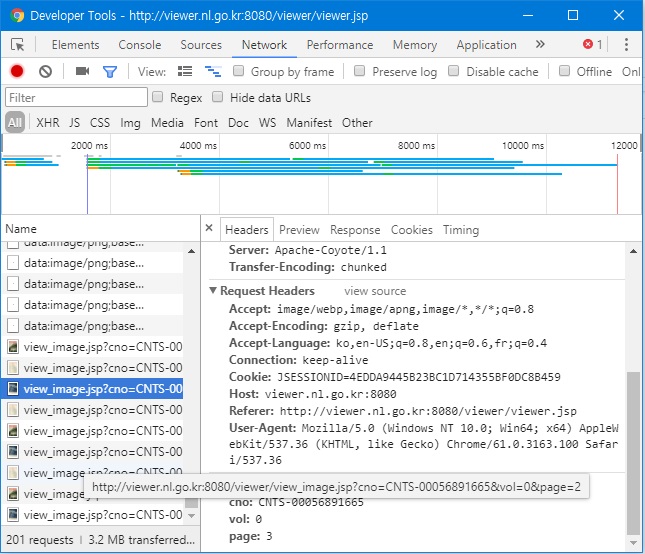
A document’s detail page contains both the document ID in its URL and its total number of pages along other metadata inside the page, within a div named “bookInfo”, so it should be fairly easy to build a scraper that would extract this information and use it to download all the picture files for any document. The only issue we might have, as we can see in the console above, is that the site uses sessions IDs to grant users permission to access the viewer, so we will have to make sure to get a valid session ID and include it as part of our HTTP request when trying to access the site from the scraper.
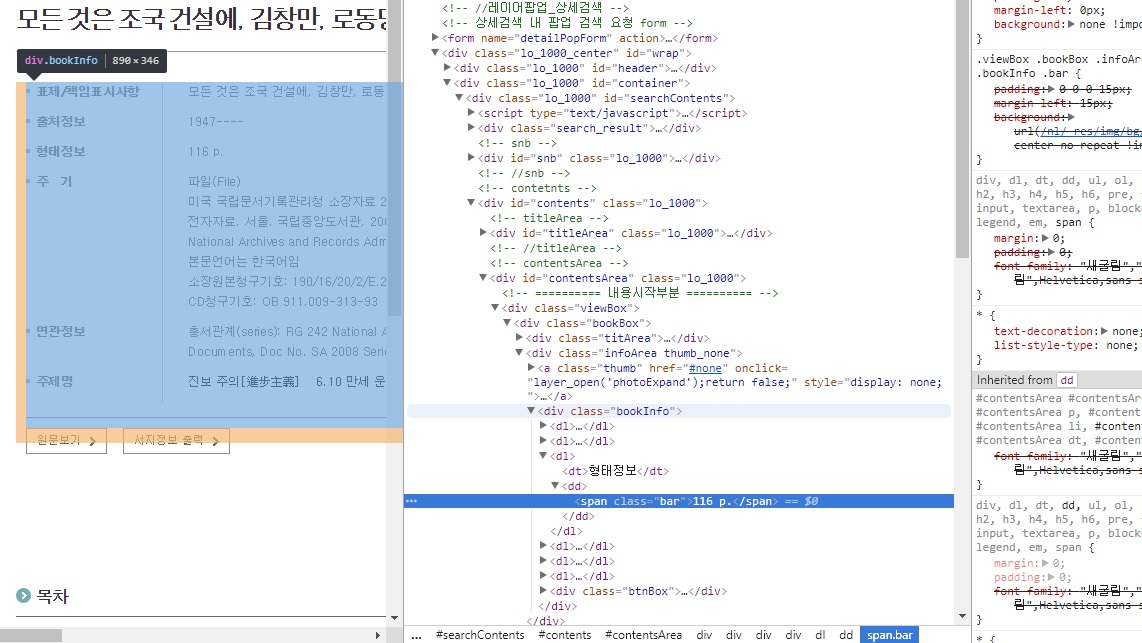
First we’ll create a Scraper class which will be initialized with the URL to the document we want to scrape. From this URL, we’ll extract the document ID and its number of pages, then send requests to download each page individually. While we’re at it, we will also extract and store the rest of the metadata available on the page, including the table of contents available in the ‘txtBox_view’ div of the detail page. All HTTP requests will be handled using the requests Python package, re will be used for regular expressions and lxml to browse and parse HTML documents. Metadata will be saved in the JSON format.
import requests
import re
import lxml.html
import json
class Scraper():
def __init__(self, url):
map_kr = ['출처정보', '형태정보', '연관정보']
map_en = ['source_info', 'pagination', 'related_info']
self.document_id = re.findall(r'contents_id=(\w*-\w*)', url)[0]
self.metadata = {'document_ID' : self.document_id}
r = requests.get(url, timeout = 10)
detail_page_tree = lxml.html.fromstring(r.content)
parse_detail_page_metadata = detail_page_tree.xpath('.//div[@class="bookInfo"]/dl')
#loop through the main metadata info
for info_block in parse_detail_page_metadata:
try:
info_type = info_block.xpath('.//dt')[0].text_content().strip()
info_content = info_block.xpath('.//dd')[0].text_content().strip()
if info_type in map_kr:
self.metadata[map_en[map_kr.index(info_type)]] = info_content
elif info_type == '주\xa0\xa0기':
dd = info_block.xpath('.//dd')[0]
for br in dd.xpath(".//br"):
br.tail = "\n" + br.tail if br.tail else "\n"
info_content = dd.text_content().split('\n')
self.metadata['main_info'] = info_content
elif info_type == '주제명':
tags = info_content.split('\xa0')
self.metadata['nl_tags'] = [tag for tag in tags if tag != '']
else:
self.metadata[info_type] = info_content
except:
print('Error while fecthing metadata')
pass
#table of contents
try:
table_content = detail_page_tree.xpath('.//div[@class="txtBox_view"]')
table_content = [t for t in table_content if '목차' in t.text_content()]
table_content = table_content[0]
for br in dd.xpath(".//br"):
br.tail = "\n" + br.tail if br.tail else "\n"
table_content = table_content.text_content()
self.metadata['table_content'] = table_content
except:
print('Error while fetching table of contents')
pass
#saves the metadata to a json file
try:
with open('metadata.json', 'w') as fp:
json.dump(self.metadata, fp)
except:
print('Error saving metadata')
pass
The __init__ function will extract the document ID from the url using a regular expression, then it will loop through all the metadata categories listed in the ‘bookInfo’ div and store them in the ‘metadata’ attribute of the class. Now given that we have the document’s ID and number of pages, scraping should be fairly straightforward. As we’ve seen in the console, the individual pages of a document all follow the same URL format (http://viewer.nl.go.kr:8080/viewer/view_image.jsp?cno=document_id_number&vol=0&page=page_number), so plugging in those two values and sending a GET request should be enough to get the content.
Let’s add a simple ‘scrape’ function to our class, which will have an optional argument to specify which pages to scrape (in case we only want certain pages rather than the whole thing). The function will format the URL with the document’s ID and the requested pages, send a GET request and save the result as a JPEG file. We’ll add a couple check to make sure the file we are downloading is not empty:
def scrape(self, download_pages = None):
url_base = 'http://viewer.nl.go.kr:8080/viewer/view_image.jsp?cno={0}&vol=0&page={1}'
pages = int(self.metadata['pagination'])
if download_pages is None:
download_pages = [i for i in range()]
for i in download_pages:
try:
print('Downloading page', i, '/', pages)
current_url = url_base.format(self.document_id, i)
r = requests.get(current_url, timeout = 10, stream = True)
if r.status_code == 200:
if len(r.content) == 0:
print('Empty content, breaking.')
with open(str(i) + '.jpg', 'wb') as fp:
fp.write(r.content)
else:
print('Error', r.status_code)
except:
print('Error downloading ppage', i, '/', pages)
pass
Unfortunately, if we try to run this, the scraper is unable to download any content and will return ‘Empty content, breaking.’ for every file it tries to download. This is because we did not specify a Session ID along with our request, which caused the server to send a 0 byte answer. We could, of course, just quickly add the Session ID we found in Chrome’s Developer Console as a cookie to our request and be done with it. But sessions expire and we would have to change the code to update the Session ID every time we tried to scrape a new document. A better solution would be to try to obtain a new session ID with every new call to scrape().
If we go back to the Developer Console in Chrome, we can see that new Session IDs are generated every time we open a new document in the Viewer. The console, however, does not tell us what requests are sent, and so we’ll have to delve a little deeper into the code, to understand how the ID is generated and validated. To do that, let’s look at what the “원문 보기” does and try to see if we can get a Session ID within our Python script by mimicking its behavior:
<div class="btnBox">
<a class="box_arrow" href="#" onclick="openviewer_popup('CNTS-00065774880');callSaveLog('CNTS-00065774880','173.239.228.92','','',' 29 ?? ???(????) ??? ??? ??? ?? ??(??), ???? ?? ??? ?? ??? ???? ??? ?? ???? ??? ??(?????? ???? ????? ????), ??????, 1948','??????????','National Archives and Records Administration','1948----','CH4C','online','CNTS-00065774880');">????</a>
<a class="box_arrow" href="#" onclick="printArea('.bookBox');">???? ??</a>
</div>
There’s a call to a function called “openviewer_popup” with the document’s ID as an argument. The function is not stored in the page’s HTML source code, but in an external Javascript file, search_common.js, where it is defined as such:
function openviewer_popup(argcno) {
var thisfrm = document.frmViewer;
//var popwidth = 1000;
//var popheight = 700;
var popwidth = screen.width;;
var popheight = screen.height;
var poptop =10;
var popleft =10;
var dt=new Date();
var getTime = dt.getHours()+""+dt.getMinutes()+""+dt.getSeconds();
if(poptop < 0) { poptop = 0; }
var winprops = "height=" + popheight + ",width=" + popwidth + ","
+ "top=" + poptop + ",left=" + popleft + ","
+ "toolbar=no,resizable=yes,location=no,status=no";
//var win_viewer = window.open("", getTime, winprops);
var win_viewer = window.open("about:blank", getTime, winprops);
thisfrm.cno.value = argcno;
thisfrm.target = getTime;
//thisfrm.action = "http://192.168.100.13/jviewer/wViewer.jsp";
thisfrm.action = "http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp";
thisfrm.submit();
}
So the code defines the various attributes (action, target, …) that will be submitted along with the form thisfrm, which refers to document.frmViewer, defined in the page’s HTML code as :
<form name="frmViewer" method="post"> <input type="hidden" name="cno" value=""> <input type="hidden" name="card_class" value="L"> </form>
So what the openviewer_popup() function does is:
- Define a popup windows’ size with the winprops and win_viewer variables (although that part of the code does not actually seem to be used at all, maybe a remnant from an older version)
- Create a variable getTime, which is a string containing the current time in the hhmmss format and sets it as the “target” attribute of the frmViewer form.
- Set the Document’s ID number as the value for the input named “cno” which is submitted along with the frmViewer form.
- Set the frmViewer’s form’s action attribute to the following URL: “http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp”
To emulate the click of the “원문 보기” button, we just need to send a similar request to the URL http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp using Python. Since no method attribute was defined for the form, the method will be the default GET. Let’s try this quickly in a Python console at first:
postRequests = {'cno': self.document_id,
'card_class': 'L',
}
r = requests.get('http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp', postRequests)
print(r.status_code)
Notice that we only pass the values of ‘cno’ (set by the openviewer_popup function) and ‘card_class’ (set in the detail page’s html code) as params to the requests. The variable getTime was only used for the target attribute, which is basically just telling the browser to create a new window for every Viewer. Since we’re only sending requests, this is irrelevant.
Now that the request went through, we can look at the cookies to see if we managed to catch a valid Session ID that we could reuse when trying to download content. We can do so by typing r.cookies in the console:
RequestsCookieJar[Cookie(version=0, name=’JSESSIONID’, value=’C1C7ED2E68BB04BB0FDA8EA72DD002E9′, port=None, port_specified=False, domain=’www.dlibrary.go.kr’, domain_specified=False, domain_initial_dot=False, path=’/JavaClient’, path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={}, rfc2109=False)]
Great! We now have a Session ID. Now we’ll create a specific get_session_id() function that will return a cookie containing the session ID which we’ll pass along with our request. As the server may also filter certain non-mainstream browsers, we’ll add a header to prevent our requests from being blocked. Here’s the updated code:
def get_session_id(self):
postRequests = {'cno': self.document_id,
'card_class': 'L',
}
r = requests.get('http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp', postRequests)
return r.cookies.get_dict()
def scrape(self, download_pages = None):
cookie = self.get_session_id()
header = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "ko,en-US;q=0.8,en;q=0.6,fr;q=0.4",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.91 Safari/537.36"}
url_base = 'http://viewer.nl.go.kr:8080/viewer/view_image.jsp?cno={0}&vol=0&page={1}'
pages = int(re.sub(r'[^0-9]', '', self.metadata['pagination']))
if download_pages is None:
download_pages = [i for i in range(pages)]
for i in download_pages:
try:
print('Downloading page', i, '/', pages)
current_url = url_base.format(self.document_id, i)
r = requests.get(current_url, headers = header, cookies = cookie, timeout = 10, stream = True)
if r.status_code == 200:
if len(r.content) == 0:
print('Empty content, breaking.')
with open(str(i) + '.jpg', 'wb') as fp:
fp.write(r.content)
else:
print('Error', r.status_code)
except:
print('Error downloading ppage', i, '/', pages)
pass
Unfortunately, that still isn’t enough and we get the same error:
Empty content, breaking.
To see what happened, let’s go back to our request and inspect its content. We’ll run this code
postRequests = {'cno': self.document_id,
'card_class': 'L',
}
r = requests.get('http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp', postRequests)
print(r.content)
Which gives us this result:
<form name='frmViewer' method='post' action='http://viewer.nl.go.kr:8080/main.wviewer'> <input type='hidden' name='cno' value='CNTS-00053799209'> <input type='hidden' name='mad' value=''> <input type='hidden' name='lip' value='127.0.0.1'> <input type='hidden' name='sysid' value=''> <input type='hidden' name='v_db' value=''> <input type='hidden' name='v_mode' value=''> <input type='hidden' name='v_doc_no' value=''> <input type='hidden' name='v_doc_id' value=''> <input type='hidden' name='sip' value='127.0.0.1'> <input type='hidden' name='f' value=''> <input type='hidden' name='card_class' value='L'> <input type='hidden' name='relate_view' value='N'> </form> <img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%20language%3D'javascript'%3Edocument.frmViewer.submit()%3B%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="<script>" title="<script>" /> </body> </html>
So the submission of the frmViewer form on the detail page actually redirects to another page, where a new request is sent to a different address and with more parameters, including our IP. We can likewise easily emulate this new request in Python. We’ll set the IP address directly in the code, but it certainly would be possible to generate it dynamically. Note also that this time, the form’s submit method is defined and set to POST. We’ll also initiate a requests Session to wrap up the two requests we’ll now be sending:
def get_session_id(self):
postRequests = {'cno': self.document_id,
'card_class': 'L',
}
postRequests2 = {'cno': self.document_id,
'mad': '',
'lip': '127.0.0.1',
'sysid': '',
'v_db': '',
'v_mode': '',
'sip': '127.0.0.1',
'f': '',
'card_class':'L',
'relate_view': 'N'}
session = requests.Session()
r = session.get('http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp', data = postRequests)
r = session.post('http://viewer.nl.go.kr:8080/main.wviewer', postRequests2)
cookie = r.cookies.get_dict()
return cookie
But before we launch the scraper, let’s first try out this new POST request in an iPython console and inspect the content of its results:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="ko">
<head>
<title>wViewer:National Library</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cstyle%20type%3D%22text%2Fcss%22%3E%20*%20%7B%20font-family%3AVerdana%2C%20Arial%2C%20Gulim%2C%20sans-serif%3B%20font-size%3A9pt%3B%20color%3A%23333%3B%20%7D%20body%20%7B%20position%3Aabsolute%3B%20overflow%3Ahidden%3B%20width%3A100%25%3B%20height%3A100%25%3B%20margin%3A0%3B%20background-color%3A%23FFF%3B%20%7D%3C%2Fstyle%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="<style>" title="<style>" />
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%20type%3D'text%2Fjavascript'%3E%0A%20%20%20%20%20%20%20%20%20var%09axyn%20%3D%20'N'%3B%0A%20%20%20%20%20%20%20%20%20var%09localIp%20%3D%20''%3B%0A%20%20%20%20%20%20%20%20%20var%09mac%20%3D%20''%3B%0A%20%20%20%20%20%20%20%20%20var%09axver%20%3D%20'0'%3B%0A%20%20%20%20%20%20%20%20%20function%20redirectPostMain()%20%7B%0A%20%20%20%20%20%20%20%20%20%09if('0'%20!%3D%20axver%20%26%26%20'2.0.0'%20!%3D%20axver)%20%7B%0A%20%20%20%20%20%20%20%20%20%09%09document.frames%5B'ifrmHelp'%5D.location%20%3D%20'viewer%2Fviewer_setup.html%23xviewer'%3B%0A%20%20%20%20%20%20%20%20%20%09%09alert(%22%EC%B5%9C%EC%8B%A0%20%EB%B7%B0%EC%96%B4%20%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%A8%20%EC%84%A4%EC%B9%98%EA%B0%80%20%ED%95%84%EC%9A%94%ED%95%98%EC%98%A4%EB%8B%88%20%5B%ED%99%95%EC%9D%B8%5D%20%EB%B2%84%ED%8A%BC%20%ED%81%B4%EB%A6%AD%20%ED%9B%84%20%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%A8%EC%9D%84%20%EC%84%A4%EC%B9%98%ED%95%B4%20%EC%A3%BC%EC%8B%9C%EA%B8%B0%20%EB%B0%94%EB%9E%8D%EB%8B%88%EB%8B%A4.%22)%3B%0A%20%20%20%20%20%20%20%20%20%09%7D%0A%20%20%20%20%20%20%20%20%20%09else%20%7B%0A%20%20%20%20%20%20%20%20%20%09%09document.getElementById('iax').value%20%3D%20axyn%3B%0A%20%20%20%20%20%20%20%20%20%09%09document.getElementById('imac').value%20%3D%20mac%3B%0A%20%20%20%20%20%20%20%20%20%09%09document.getElementById('ilip').value%20%3D%20localIp%3B%0A%20%20%20%20%20%20%20%20%20%09%09document.getElementById('frmIdMain').submit()%3B%0A%20%20%20%20%20%20%20%20%20%09%7D%0A%20%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%20%20%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="<script>" title="<script>" />
</head>
<body scrolling='no'>
<iframe name='ifrmHelp' src='' frameborder='0' style='width:100%; height:100%; margin:0; border:none;'></iframe>
<form id='frmIdMain' name='frmMain' method='post' target='_self' action='./main.wviewer'>
<input type='hidden' id='iid' name='cno' value='CNTS-00053799209' />
<input type='hidden' id='iuid' name='uid' value='' />
<input type='hidden' id='iugrp' name='ugrp' value='' />
<input type='hidden' id='iax' name='ax' value='N' />
<input type='hidden' id='imac' name='mac' value='' />
<input type='hidden' id='ilip' name='lip' value='' />
<input type='hidden' id='isip' name='sip' value='127.0.0.1' />
<input type='hidden' id='card_class' name='card_class' value='L' />
</form>
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%20type%3D'text%2Fjavascript'%3EredirectPostMain()%3B%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="<script>" title="<script>" />
</body>
</html>
<form name='frmViewer' method='post' action='http://viewer.nl.go.kr:8080/main.wviewer'>
<input type='hidden' name='cno' value='CNTS-00053799209'>
<input type='hidden' name='mad' value=''>
<input type='hidden' name='lip' value='127.0.0.1'>
<input type='hidden' name='sysid' value=''>
<input type='hidden' name='v_db' value=''>
<input type='hidden' name='v_mode' value=''>
<input type='hidden' name='v_doc_no' value=''>
<input type='hidden' name='v_doc_id' value=''>
<input type='hidden' name='sip' value='127.0.0.1'>
<input type='hidden' name='f' value=''>
<input type='hidden' name='card_class' value='L'>
<input type='hidden' name='relate_view' value='N'>
</form>
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%20language%3D'javascript'%3Edocument.frmViewer.submit()%3B%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="<script>" title="<script>" />
</body>
</html>
Here is a new redirection, but this time the page also checks to see if our browser has the Viewer’s plug-in installed. If not, it will display an error message instructing the user to download and install it. If it is installed, the page will send yet another POST request with new parameters. The values of these parameters are assigned in the HTML body at the time when the form is defined, but a few see their values updated in the Javascript that checks the plug-in’s presence and submits the form. To bypass the plug-in check, we can therefore simply just send this final POST request directly through Python:
def get_session_id(self):
postRequests = {'cno': self.document_id,
'card_class': 'L',
}
postRequests2 = {'cno': self.document_id,
'mad': '',
'lip': '127.0.0.1',
'sysid': '',
'v_db': '',
'v_mode': '',
'sip': '127.0.0.1',
'f': '',
'card_class':'L',
'relate_view': 'N'}
postRequests3 = {'cno': self.document_id,
'uid': '',
'ugrp' : '',
'ax' : 'N',
'mac' : '',
'lip' : '',
'sip' : '127.0.0.1',
'card_class': 'L',
'iax' : 'N',
'ilip': '127.0.0.1',
'imac': ''}
session = requests.Session()
r = session.get('http://www.dlibrary.go.kr/JavaClient/jsp/dasen/viewWonmun_js.jsp', data = postRequests)
r = session.post('http://viewer.nl.go.kr:8080/main.wviewer', postRequests2)
cookie = r.cookies.get_dict()
r = session.post('http://viewer.nl.go.kr:8080/main.wviewer', postRequests3)
return cookie
If we check the content of the response to this last request in an iPython console, we finally get the sourcecode of the Viewer page. We can now launch our scraper and try to get a full document:

The full code is available on GitHub.