
An attempt to develop a quick and dirty method to automatically transliterate Korean using the McCune-Reischauer system with NLP, neural networks and character level sequence to sequence models.
0. Introduction
I recently uploaded a series of new documents to the site’s archive, which required me to romanize the title and authors’ names for each of the entries. There are many different ways to transliterate Korean to the roman alphabet, although the South Korean Ministry of Culture’s Revised Romanization and the McCune-Reischauer system are by far the most commonly used. Revised Romanization (RR) is the official system in South Korea and McCune-Reischauer (MCR) is used in Western academia and serves as a basis for the North’s own romanization system. The romanized metadata for documents indexed on this website also follows the MCR system. Assessing each system’s merits and demerits is beyond the scope of this blog post, but one thing that MCR is often criticized for is its complexity. One of its creators, Edwin Reischauer acknowledged as much in a 1980 letter detailing the genesis of the system:
You were kind enough to send me a copy of your letter about the McCune-Reischauer system for transliterating Korean which you wrote to our mutual friend Professor Suh, and I feel that I owe you a few points of correction and explanation.
First, I was a Harvard graduate student in my seventh year of graduate study and temporarily living in Korea when we devised the system, but McCune never had any relationship of any sort with Harvard. Second, we did it at my suggestion because I found absolutely no uniform system of any sort, and I needed something for the Korean names that appeared in my studies on the travels of the monk Ennin (838-845). I therefore suggested to McCune that at least he and I might agree on a system we two used in common. Third, we had copious advice from Korean linguists and phoneticians, because phonetics and linguistics were among the few fields Korean scholars felt safe in studying during those days of extreme Japanese intellectual oppression. In a sense we had too much ‘expert phonetic’ advice, which tended to make the system too phonetically precise and therefore too complex. Fourth, in the autumn of 1937 it was hard to imagine any time soon when Korea would be free and a Korean transcription system would have a wide practical use, so we designed our system with only scholars in mind and tried to make it conform so far as possible to the other East Asian transcription system Wade-Giles for Chinese and Hepburn for Japanese. If I had any idea that Korea would soon be a free nation again and Korean transcriptions widely used, I would have tried to make a more practical and simpler system in which newspaper and scholarly usage would not of necessity have to diverge. Fifth, I wish very much that a uniform system that everyone would use for both scholarly and popular use will be worked out and adopted. What is not tolerable is that most people and institutions still go their own many independent ways to the utter confusion of everyone.
Cited in 김기중, 現行 “로마字 表記法”의 문제점 : McCune-Reischauer System을 비판함, (광주개방대학 논문집, Vol.3, 1986)
As a result, the Library of Congress’ guidelines for the romanization of Korean following the MCR system totals 65 pages, three times longer than the ones for Japanese or Chinese. To make things worse, the application of certain rules, such as the hyphenations of personal names are not consistent across publications and institutions. It is therefore perhaps unsurprising that very few solutions exist to automate the process of romanization with MCR. To my knowledge, the only resources currently available are the University of Pusan’s Korean Romanization Converter, the Library of Gottingen’s Hangul-Konverter and Ushuaia.pl’s multilingual transliteration tool. The latter two follow the same algorithm regardless of the input, while the former tries to address the specific romanization rules for people’s names and toponyms (the user, however, has to manually select the type of the input to get the proper romanization). Neither provide word division, nor automated capitalization and hyphenation for proper nouns. Such a task is indeed far from trivial, as it would imply to perform named entity recognition to separate toponyms and personal names as well as to develop a sentence segmenter that would follow MCR’s specific rules.
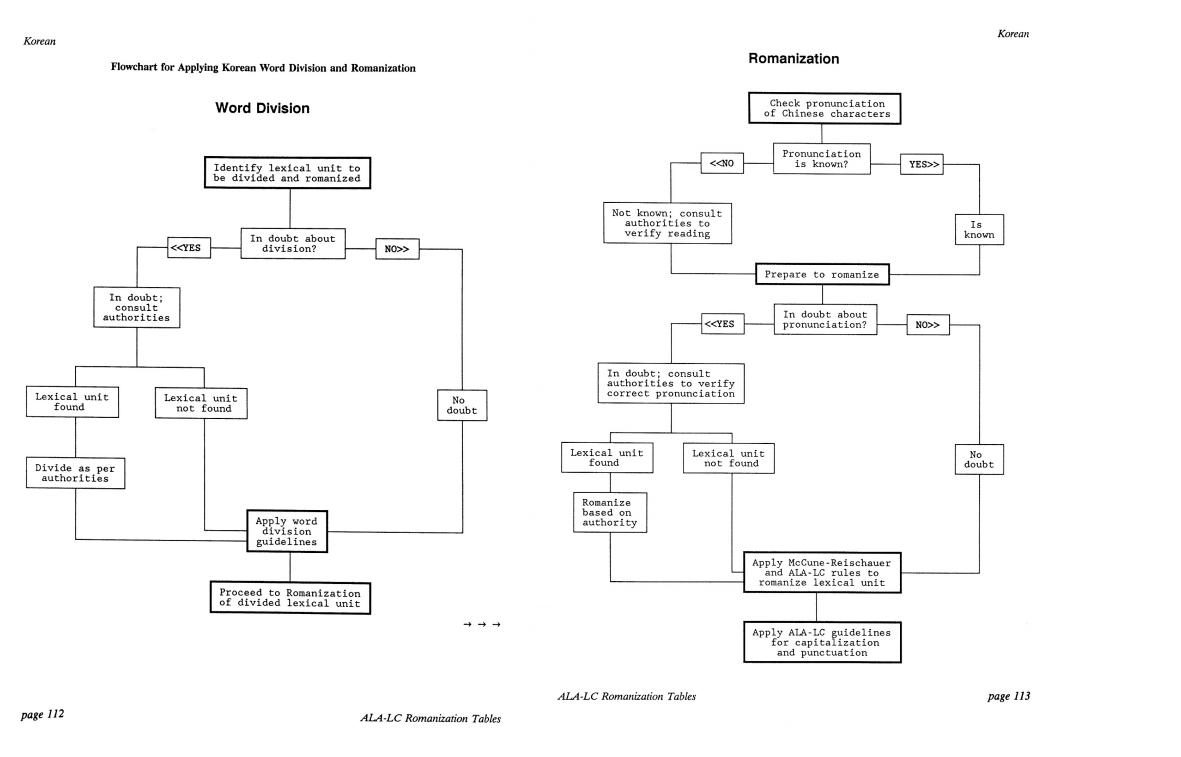
With some time, energy and some good dictionaries or gazetteers, it would certainly be possible to develop a robust tool to automate the whole process. But the prospect of hand coding all the various rules seemed far too tedious for a simple holiday-season coding project, so letting a machine learn the rules and do the job instead sounded like a decent alternative. It would also be interesting to see the results we could get with some basic data mining and machine learning.
1. Sequence-to-sequence models
Sequence to sequence neural network models have recently gained widespread interest for their performance in tasks such as machine translation. Sequence to sequence models can take a sequence of variable length, such as a sentence in language A, as input and output another sequence of differing length, such as the translation of the sentence in language B. The model’s architecture thus consists of an encoder, usually some brand of recurrent neural network, which takes the input sentence and encodes it as a “thought vector”, an abstract, fixed-length, numerical representation of the sequence which is then used as a hidden state for another RNN, the decoder.
The decoder is fed a “beginning of sequence” tag as an input and tries to predict the first item in the sequence, then that item is used to predict the next one, and so on until it predicts an “end of sequence”. For sentences, the decoder thus works like a traditional language model in that it tries to predict the next word based on the previous ones in the sentence. But traditional model languages’s predictions are usually based only on a few previous words, due to limitations on training data and computational capacity. On the other hand, our decoder will benefit from RNN’s ability to model long distance dependencies and from the context provided by the thought vector.
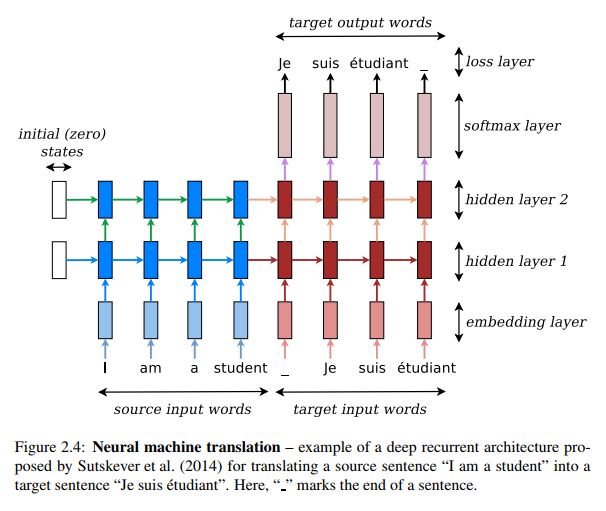
We could frame the issue of transliteration as a sequence to sequence translation system where we match a sentence written in Hangul/Chosongul to a romanized sentence. Theoretically, the model might even be able to learn the capitalization and division rules to properly render Hangul words such as “조선인민민주주의공화국” into “Chosŏn inmin minjujuŭi kongwaguk”. In practice, however, we would need a very large dataset to be able to get such performance. And since the main use of MCR is to render bibliographical information in academic literature and library catalogs, there is no way we could ever find enough training data.
But the sequence does not necessarily need to be a series of word. It is perfectly possible to work on character-level language models. Instead of romanizing whole sentences (or, more likely, book titles) we would proceed word by word, predicting the most likely transliteration for each Hangul character. Although we would have to find a way to handle the text segmentation at some point, this would drastically reduce the amount of training data needed. The length of the sequences would also be much more consistent, removing the potential need for bucketing.
Fortunately, the Python library Keras comes with a sample sequence to sequence script. To try it out quickly, I created a small dataset of Korean names both in Hangul and MCR Romanization from Wikipedia pages. The name list is actually a good example of the difficulties posed by MCR as first names are inconsistently hyphenated. Creating an algorithm that can follow the hyphenation rule but still handle the proper romanization of “Western” names such as 라파엘 or 웬디 without any hyphens, or of stage names such as “MC 몽” would not be a walk in the park. But let’s put those issues aside and proceed with testing. The model is already set up and we only have to modify a few parameters to fit our data. First we’ll change:
batch_size = 64 # Batch size for training. epochs = 100 # Number of epochs to train for. latent_dim = 256 # Latent dimensionality of the encoding space. num_samples = 10000 # Number of samples to train on. # Path to the data txt file on disk. data_path = 'fra-eng/fra.txt'
into:
batch_size = 64 # Batch size for training. epochs = 50 # Number of epochs to train for. latent_dim = 256 # Latent dimensionality of the encoding space. num_samples = 1350 # Number of samples to train on. # Path to the data txt file on disk. data_path = 'names.txt'
The only things that change are the source file for the data set and the number of samples, as we only have 1350. Once the training is over, the script displays some examples of decoded/encoded sequences:
Input sentence: 임태희 Decoded sentence: Im T'aehŭi - Input sentence: 정한 Decoded sentence: Chŏng Han - Input sentence: 정용주 Decoded sentence: Chŏng Yong-chu - Input sentence: 고낙춘 Decoded sentence: Ko Rak-ch'un - Input sentence: 전효성 Decoded sentence: Chŏn Hyo-sŏng - Input sentence: 한현희 Decoded sentence: Han Hyŏnhŭi
The results look good, but keep in mind that the input sentences are taken from the training set it’s nothing to write home about so far. To test with new names, we’ll have to add a small function to convert a string into a vector we can send to the decoder:
def encode_input(name):
test_input = np.zeros(
(1, max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
for t, char in enumerate(name):
test_input[0, t, input_token_index[char]] = 1.
return test_input
We can now try out new names:
decode_sequence(encode_input('김일성'))
Out[23]: 'Kim Sŏlsin\n'
decode_sequence(encode_input('김정일'))
Out[24]: 'Kim Chŏngsu\n'
It’s not terrible, but it’s not great either. But that was to be expected, since if we look at the training log, the model had actually been overfitting for several epochs:
Epoch 97/100 1079/1079 [==============================] - 2s 2ms/step - loss: 0.0147 - val_loss: 0.6714 Epoch 98/100 1079/1079 [==============================] - 2s 2ms/step - loss: 0.0084 - val_loss: 0.7025 Epoch 99/100 1079/1079 [==============================] - 2s 2ms/step - loss: 0.0205 - val_loss: 0.6724 Epoch 100/100 1079/1079 [==============================] - 2s 2ms/step - loss: 0.0074 - val_loss: 0.7451
We could decrease the number of epochs, but given how little training data we have, it is unlikely that we would see a significant improvement. One more thing we should notice is that all the syllables from the two names we tried (김, 정, 일, 성) were present in our training set. But if we try to include more ‘exotic’ characters that are unlikely to be in common names, we’ll run into trouble:
decode_sequence(encode_input('김일객'))
Traceback (most recent call last):
File "<ipython-input-29-3bd2c5b169e7>", line 1, in <module>
decode_sequence(encode_input('김일객'))
File "<ipython-input-22-216bb5b25c3b>", line 6, in encode_input
test_input[0, t, input_token_index[char]] = 1.
KeyError: '객'
To avoid such errors, we would need to have all eleven thousand and something possible Korean characters in our training dataset which would greatly impair performance.
2. From character-level to jamo-level
The reason there are so many different Korean characters is because each character is actually a block combining different letters or “jamo” (자모). There are 40 letters (19 consonants and 21 vowels) total, which greatly reduces the potential dimension of our input vectors. Switching to a jamo-level will also likely improve performance as, for MCR, this is a much more relevant level than the character/block level.
But before we can do so, we need a way to decompose each unicode Hangul character into its constituent jamo. Fortunately, this isn’t a very hard task. The documentation of the Unicode Standard provides a very detailed explanation of how to arithmetically decompose or recompose a Hangul block based on its Unicode value There are even pseudo-code and Java examples, which are easily translatable into python. I’ve saved the function with the algorithm in a separate file called jamo.py which we will then be able to import into other scripts. I’ve added an optional extra argument to return an empty final jamo when the character does not have a bottom jamo:
#constants
SBase = 0xAC00
LBase = 0x1100
VBase = 0x1161
TBase = 0x11A7
LCount = 19
VCount = 21
TCount = 28
NCount = 588
SCount = 11172
def decompose_character(char, final_char = False):
char = ord(char)
SIndex = char - SBase
if (SIndex < 0 or SIndex >= SCount):
return [chr(char)]
result = []
L = int(LBase + SIndex / NCount)
V = int(VBase + (SIndex % NCount) / TCount)
T = int(TBase + SIndex % TCount)
result.append(chr(L))
result.append(chr(V))
if final_char:
result.append(chr(T))
elif (T != TBase):
result.append(chr(T))
return result
Now we only need to slightly alter the way input vectors are generated at the beginning of our Keras script:
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
input_lengths = []
lines = open(data_path, encoding = 'utf-8').read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
if line != '':
input_text, target_text = line.split('\t')
cur_input_length = 0
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
jamos = decompose_character(char)
cur_input_length += len(jamos)
for jamo in jamos:
if jamo not in input_characters:
input_characters.add(jamo)
input_lengths.append(cur_input_length)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max(input_lengths)
max_decoder_seq_length = max([len(txt) for txt in target_texts])
And we can now re-train the model and try again:
decode_sequence(encode_input('김일성'))
Out[45]: 'Kim Il-il\n'
decode_sequence(encode_input('김정일'))
Out[46]: 'Kim Chǒngbim\n'
decode_sequence(encode_input('김일객'))
Out[47]: 'Kim Kiri\n'
The algorithm performed slightly better on 김일성 this time and was also able to handle an attempt at romanizing 김일객, even though the character 객 did originally not appear in the training set. This is starting to look promising, so we can try and train it with more data. There used to be a romanization dictionary with over 80,000 entries available on romanization.org but the site is now defunct and its data unavailable.
To get data, I scraped bibliographical information from the online catalogs of various university libraries which use MCR and supplemented with information from a transliteration table for single characters. I then applied some basic heuristics to clean up the raw data a little bit. This includes converting hanjas to their most likely Hangul version using the hanja Python package, making sure that the number of words in both the Hangul and Romanized sentences are the same so we can match words in both sentences one to one and filtering out non-hangul words and some obvious aberrations (length of romanized string smaller than the original Hangul one):
translator=str.maketrans('','',string.punctuation+'·')
wordlist = defaultdict(list)
for i, col in enumerate(col1):
try:
splits_han = col.split()
splits_rom = col2[i].split()
if len(col2[i].translate(translator).split()) != len(col.translate(translator).split()):
continue
for j, split in enumerate(splits_han):
if hanja.hangul.contains_hangul(split) and not (len(split) > len(splits_rom[j])):
wordlist[hanja.translate(split, 'substitution')].append(splits_rom[j].lower())
except:
pass
For each Hangul words, the different corresponding romanizations found across the corpus are stored in a list. The lists are generally quite homogeneous, indicating consistent romanization practices across libraries, but there are a few errors here and there. For each Hangul word I went with the most commonly used romanization. Finally I removed the hyphenation in the romanization for proper names using, again, a simple heuristic script:
for key in wordlist:
if all(hanja.hangul.is_hangul(c) for c in key) and len(key) == 2 and '-' in wordlist[key]:
wordlist[key] = wordlist[key].replace('-', '')
The result is a wordlist of slightly less than 50,000 entries, which we can now use to train our model. After a few hours of training, the evaluation metrics look promising:
Epoch 96/100 37907/37907 [==============================] - 155s 4ms/step - loss: 0.0018 - val_loss: 0.0578 Epoch 97/100 37907/37907 [==============================] - 155s 4ms/step - loss: 0.0018 - val_loss: 0.0585 Epoch 98/100 37907/37907 [==============================] - 154s 4ms/step - loss: 0.0018 - val_loss: 0.0571 Epoch 99/100 37907/37907 [==============================] - 154s 4ms/step - loss: 0.0018 - val_loss: 0.0579 Epoch 100/100 37907/37907 [==============================] - 155s 4ms/step - loss: 0.0017 - val_loss: 0.0596
We could most likely have got very slightly better results by reducing the numbers of Epochs, but this is already very satisfactory. Let’s see how we fare with some words that did not appear in the original training set:
decode_sequence(encode_input('얼룩말'))
Out[11]: 'ŏllungmal\n'
decode_sequence(encode_input('작가론'))
Out[12]: 'chakkaron\n'
decode_sequence(encode_input('막걸리'))
Out[13]: 'makkŏlli\n'
Even proper names are now handled adequately, although they lack the proper division, capitalization and hyphenation:
decode_sequence(encode_input('김일성'))
Out[14]: 'kimilsŏng\n'
Although there are still a few blunders that a simple substitution algorithm would have handled better:
decode_sequence(encode_input('담배'))
Out[17]: 'tampae\n'
This particular case is most likely due to the presence in the training data of words such as “문법” or “헌법” which are romanized as munpŏp and hŏnpŏp because of their reinforced medial consonant. Words which actually do follow the general romanization rules such as 냄비 (naembi) or 담배 (tampae) are actually much more common words, but they’re unlikely to appear in bibliographical references. Despite a few errors here and there, overall the model handles pronuciation-based exceptions quite decently compared to what a simple rule-based algorithm with no dictionary would do, especially considering how little effort when into collecting and cleaning the data:
decode_sequence(encode_input('옛날'))
Out[27]: 'yennal\n'
decode_sequence(encode_input('평가'))
Out[28]: "p'yŏngka\n"
decode_sequence(encode_input('물리학'))
Out[29]: 'mullihak\n'
decode_sequence(encode_input('헛일'))
Out[30]: 'hŏsil\n'
However, performance quickly degrades with longer words as words of more than 3 characters only account for 3% of the training corpus:
decode_sequence(encode_input('예술지상주의'))
Out[43]: 'yesulchisangjudi\n'
decode_sequence(encode_input('오감스럽다'))
Out[44]: 'ogamsŭldŏsŭ\n'
And words longer than 10 characters are simply not handled:
decode_sequence(encode_input('조선인민민주주의공화국'))
Traceback (most recent call last):
File "<ipython-input-47-b786dbaa1ca1>", line 1, in <module>
decode_sequence(encode_input('조선인민민주주의공화국'))
File "F:/Code Projects/Translit/test_keras/lstm_seq2seq_char_ko.py", line 246, in encode_input
test_input[0, index, input_token_index[jamo]] = 1.
IndexError: index 27 is out of bounds for axis 1 with size 27
This happens because their length exceed that of the longest word available in the training corpus. But this is not really a major issue. First, we could easily increase the maximum possible length. Two, long words such as ‘조선인민민주주의공화국’ would actually have to be broken down into their constituent parts of speech (‘조선’, ‘인민’, ‘민주주의’, ‘공화국’) before being fed to the algorithm. We currently have no way of automatically doing this, so we will have to think of something new.
3. Implementing word division with Conditional Random Fields
The issue of sentence segmentation / word division in East Asian language is not a trivial one. Unlike Japanese and Chinese, however, most contemporary Korean texts already use spacing. But this will not make our task much easier. The way MCR divides words has more to do with grammar and phonetics than with actual usage, so trying to directly infer segmentation based on patterns found in a dataset of existing Korean texts would not work. A part-of-speech tagger could be useful as it might be able to break down sentences into their grammatical components regardless of spacing. However it is worth noting that MCR’s word division rules are, once again, somewhat peculiar and won’t perfectly match the results of a traditional tagger.
One option would be to use the results given by a POS tagger and process them using a fixed sets of if/then rules and some dictionary for exceptions. This would surely prove effective but also terribly boring to code. Furthermore it’s worth noting that because spacing can affect the output of the POS tagger, this solution might not be sufficient to handle an exotic or utter lack of spacing. A slightly more interesting way to go about this would be to try to train an algorithm to emulate the spacing patterns found in the bibliographical data we’ve scraped.
We can treat word division as a classic sequence labeling problem in which each character in the sentence is assigned a label depending on whether it ends a word or not. Before attempting to deploy a deep-learning model, we can try a more traditional machine learning approach using Conditional Random Fields (CRF) and see how we fare. CRFs have long been a method of choice for sequence labeling tasks, and have been used successfully to segment Chinese text, although significantly better results have recently been achieved on a number of NLP tasks by deep learning models. The higher performance of deep learning models, however, is highly dependent on the amount of training data. Given the limited amount of data we have at our disposal (slightly over 80,000 sentences), it is worth trying a simple implementation of CRFs with basic traditional features.
We’ll use the CRFSuite package for Python and start with a very basic set of features, based only on the various jamo composing a character. In Unicode, each Korean character can be split into three jamo (초성, 중성, 종성) although for characters like 가 or 비 the final jamo would be empty. We’ll take this jamo-level decomposition as the main way to represent a character for our model and we’ll use fixed values when a character is a punctuation sign, a number, a latin alphabet letter or something else entirely. We’ll first only use the representation of the character whose label we are trying to predict and the representations of the next and previous characters as features for the model.
First, we’ll read in the data and create the sequences. For sentences, we remove all spacing to only have a sequence of characters, each of which will be assigned a number (0 or 1) depending on whether it ends a word (i.e. is followed by spacing in the original sentence) or not:
import pycrfsuite
from jamo import decompose_character
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from itertools import chain
from sklearn.preprocessing import LabelBinarizer
from hanja import hangul
import string
import pandas as pd
sentences = pd.read_csv('data/bibliographical_data.csv', encoding = 'utf8', sep = '\t', header = None)[0]
no_space_sentences = []
character_labels = []
for sentence in sentences:
words = sentence.split()
no_space_sentences.append()
character_labels.append([str(_) for word in words for _ in (([0] * (len(word) - 1)) + [1])])
Then we’ll define the functions to extract the features from each sentence:
def get_jamos(character):
if hangul.is_hangul(character):
character_jamos = decompose_character(character, final_char = True)
elif character in string.punctuation:
character_jamos = ['.', '.', '.']
elif character.isdigit():
character_jamos = ['0', '0', '0']
elif character.isalpha():
character_jamos = ['a', 'a', 'a']
else:
character_jamos = ['x', 'x', 'x']
return character_jamos
def character_features(sentence, index):
character = sentence[index]
character_jamos = get_jamos(character)
features = ['bias',
'jamo1=' + character_jamos[0],
'jamo2=' + character_jamos[1],
'jamo3=' + character_jamos[2]]
if index > 0:
character_before_jamos = get_jamos(sentence[index - 1])
features.extend(['before-jamo1=' + character_before_jamos[0],
'before-jamo2=' + character_before_jamos[1],
'before-jamo3=' + character_before_jamos[2]])
else:
features.append('BOS')
if index < len(sentence) - 1:
character_after_jamos = get_jamos(sentence[index + 1])
features.extend(['after-jamo1=' + character_after_jamos[0],
'after-jamo2=' + character_after_jamos[1],
'after-jamo3=' + character_after_jamos[2]])
else:
features.append('EOS')
return features
def create_sentence_features(sentence):
return [character_features(sentence, i) for i in range(len(sentence))]
Finally we’ll train and evaluate the model, following the examples provided by the CRFSuite’s documentation:
def bio_classification_report(y_true, y_pred):
lb = LabelBinarizer()
y_true_combined = lb.fit_transform(list(chain.from_iterable(y_true)))
y_pred_combined = lb.transform(list(chain.from_iterable(y_pred)))
tagset = set(lb.classes_) - {'O'}
tagset = sorted(tagset, key=lambda tag: tag.split('-', 1)[::-1])
class_indices = {cls: idx for idx, cls in enumerate(lb.classes_)}
return classification_report(
y_true_combined,
y_pred_combined,
labels = [class_indices[cls] for cls in tagset],
target_names = tagset,
)
X = [create_sentence_features(sentence) for sentence in no_space_sentences]
X_train, X_test, y_train, y_test = train_test_split(X, character_labels, test_size=0.3, random_state=777)
trainer = pycrfsuite.Trainer(verbose=False)
for xseq, yseq in zip(X_train, y_train):
trainer.append(xseq, yseq)
trainer.set_params({'c1': 1.0,
'c2': 1e-3,
'max_iterations': 50,
'feature.possible_transitions': True})
trainer.train('MCR-segmentation')
tagger = pycrfsuite.Tagger()
tagger.open('MCR-segmentation')
y_pred = [tagger.tag(xseq) for xseq in X_test]
print(bio_classification_report(y_test, y_pred))
Training only takes a couple of minutes and the model’s performance is not too shabby given the limited number of features, but it’s not exactly good either:
precision recall f1-score support
0 0.80 0.82 0.81 219677
1 0.77 0.74 0.75 178319
avg / total 0.78 0.78 0.78 397996
Trying the model with the word 조선인민민주주의공화국 gives us:
tagger.tag(create_sentence_features()) Out[14]: ['0', '1', '0', '1', '0', '0', '1', '1', '1', '0', '1']
Or 조선 인민 민주주 의 의 공 화국, instead of 조선 인민 민주주의 공화국. Close, but not quite there yet. Let’s see if we can improve the results, by extending the window to the n-2 and n+2 characters and by incorporating full character and bigram/trigram information rather than just jamo:
def character_features(sentence, index):
character = sentence[index]
character_jamos = get_jamos(character)
features = ['bias',
'char=' + character,
'jamo1=' + character_jamos[0],
'jamo2=' + character_jamos[1],
'jamo3=' + character_jamos[2]]
if index > 0:
character_before_jamos = get_jamos(sentence[index - 1])
features.extend(['before-char=' + sentence[index - 1],
'before-bigram=' + sentence[index - 1] + character,
'before-jamo1=' + character_before_jamos[0],
'before-jamo2=' + character_before_jamos[1],
'before-jamo3=' + character_before_jamos[2]])
else:
features.append('BOS')
if index < len(sentence) - 1:
character_after_jamos = get_jamos(sentence[index + 1])
features.extend(['after-char=' + sentence[index + 1],
'after-bigram=' + character + sentence[index + 1],
'after-jamo1=' + character_after_jamos[0],
'after-jamo2=' + character_after_jamos[1],
'after-jamo3=' + character_after_jamos[2]])
else:
features.append('EOS')
if index > 1:
character_before_jamos = get_jamos(sentence[index - 2])
features.extend(['before2-char=' + sentence[index - 2],
'before2-bigram=' + sentence[index - 2] + sentence[index - 1],
'before2-trigram=' + sentence[index - 2] + sentence[index - 1] + character,
'before2-jamo1=' + character_before_jamos[0],
'before2-jamo2=' + character_before_jamos[1],
'before2-jamo3=' + character_before_jamos[2]])
else:
features.append('BOS')
if index < len(sentence) - 2:
character_after_jamos = get_jamos(sentence[index + 2])
features.extend(['after2-char=' + sentence[index + 2],
'after2-bigram=' + sentence[index + 1] + sentence[index + 2],
'after2-trigram=' + character + sentence[index + 1] + sentence[index + 2],
'after2-jamo1=' + character_after_jamos[0],
'after2-jamo2=' + character_after_jamos[1],
'after2-jamo3=' + character_after_jamos[2]])
else:
features.append('EOS')
return features
And the evaluation results:
precision recall f1-score support
0 0.98 0.98 0.98 219677
1 0.98 0.97 0.97 178319
avg / total 0.98 0.98 0.98 397996
And if we now try again with ‘조선인민민주주의공화국’, we get a proper segmentation:
tagger.tag(create_sentence_features()) Out[4]: ['0', '1', '0', '1', '0', '0', '0', '1', '0', '0', '1']
4. Putting it all together
Now that we have a decent model, all we need is to re-train it using the entire dataset and start implementing it. To that end, we’ll create a Romanizer() class and start by adding a function for segmenting a Korean text:
import pycrfsuite
from tools.vectorizer import create_sentence_features_crf
import re
class Romanizer():
def __init__(self):
self.__segmenter = pycrfsuite.Tagger()
self.__segmenter.open('models/MCR-segmentation')
def Segment(self, text):
sentences = re.split(r'(?<=\.) ', text)
no_space_sentences = []
segmented_sentences = []
delimiters = []
for sentence in sentences:
no_space_sentence = ()
no_space_sentences.append(no_space_sentence)
delimiters.append(self.__segmenter.tag(create_sentence_features_crf(no_space_sentence)))
for i, delimiter in enumerate(delimiters):
current_sentence = ''
for j, label in enumerate(delimiter):
current_sentence += no_space_sentences[i][j]
if label == '1' and j != len(delimiter) - 1:
current_sentence += ' '
segmented_sentences.append(current_sentence)
return '. '.join(segmented_sentences).strip()
Let’s do some tests with random articles from DBPia:
r.Segment('과학적 세계관과 인간관')
Out[54]: '과학적 세계관 과 인간관'
r.Segment('경판 30장본 <홍길동전>과 박태원의 <홍길동전>의 기호학적 비교 연구')
Out[55]: '경판 30장본 < 홍 길동 전> 과 박 태원 의 <홍 길동 전> 의 기호학적 비교 연구'
r.Segment('홍대지역 문화유민의 흐름과 대안적 장소의 형성')
Out[56]: '홍대 지역 문화 유민 의 흐름 과 대안적 장소 의 형성'
r.Segment('생물학적 죽음에서 인간적 죽음으로')
Out[57]: '생물학적 죽음 에서 인간적 죽음 으로'
r.Segment('대한민국의 법치민주주의는 살아있는가? : 헌법재판소의 통합진보당 정당해산판결을 중심으로')
Out[58]: '대한 민국 의 법치 민주주의 는 살아 있는가? : 헌법 재판소 의 통합 진보당 정당 해산 판결 을 중심 으로'
All good! Now all we need to do is add in the word-romanization code:
import pycrfsuite
import re
import pickle
from tools.vectorizer_crf import create_sentence_features_crf
from tools.keras_predict import Translit
from keras.models import load_model
class Romanizer():
def __init__(self):
self.__segmenter = pycrfsuite.Tagger()
self.__segmenter.open('models/MCR-segmentation')
romanizer_model = load_model('models/s2s.h5')
with open('models/input_token_index.dat', 'rb') as fp:
input_token_index = pickle.load(fp)
with open('models/target_token_index.dat', 'rb') as fp:
target_token_index = pickle.load(fp)
self.__romanizer = Translit(romanizer_model, input_token_index, target_token_index)
def Romanize(self, text, return_array = False):
sentences = self.Segment(text, return_array = True)
romanized_sentences = []
for sentence in sentences:
words = sentence.split()
romanized_sentence = ''
for word in words:
romanized_sentence += self.__romanizer.Romanize(word) + ' '
romanized_sentences.append(romanized_sentence.strip(' '))
if return_array:
return romanized_sentences
return '. '.join(romanized_sentences).strip()
The Translit object handles all the operations with Keras and is defined in a separate file. There is no need to go over it here as most of the code has already been covered in the earlier part of this post. The only new bit is about loading the model we saved earlier after training and extracting the decoder and encoder from it. We can retrieve the models and their states from the dumped h5 file as such:
from keras.models import load_model
model = load_model('s2s.h5')
encoder = model.layers[2]
encoder_inputs = model.layers[0].input
encoder_outputs, state_h, state_c = model.layers[2].output
encoder_states = [state_h, state_c]
decoder_inputs = model.layers[1].input
decoder_lstm = model.layers[3]
decoder_dense = model.layers[-1]
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
Feel free to explore the full source code on Github. Now that the object is set up properly, we can run a few tests:
r.Romanize('분단 기억과 가족 서사 : 김원일의 손풍금을 중심으로')
Out[30]: "pundan kiŏk kwa kajok sŏsa : kim wŏnil ŭi son p'unggŭm ŭl chungsim ŭro"
r.Romanize('한국 장애인 문학의 새로운 지평 : 김미선의 소설을 중심으로')
Out[31]: "han'guk changae inmunhak ŭi saeroun chip'yŏng : kim misŏn ŭi sosŏl ŭl chungsim ŭro"
r.Romanize('작가의 정체성과 개작, 그리고 평가 : 황순원 "움직이는 성"의 개작을 중심으로')
Out[32]: "chakka ŭi chŏngch'esŏng kwa kaejak kŭrigo p'yŏngka : hwang sunwŏn umjiginŭn sŏng ŭi kaejak ŭl chungsim ŭro"
r.Romanize('한국 소설 속에 나타난 인민재판의 양상 : 황순원 장용학 조정래의 소설을 중심으로')
Out[33]: "han'guk sosŏl sok e nat'anan inmin chaep'an ŭi yangsang : hwang sunwŏn chang yonghak cho chŏngnae ŭi sosŏl ŭl chungsim ŭro"
Overall, there are very few mistakes both in the segmentation and romanization.
Some ways to improve the application in the future would be: