
Reverse engineering North Korean dictionary software to export the data to a more accessible format. Reading into North Korean software protection schemes, encoding formats and database indexing. Dealing with OOP code in Ghidra. Experimenting with Rust to create a TUI app for the extracted dictionaries.
0. Introduction
1. Biyak Technoscientific Dictionary (비약과학기술용어사전)
1.1. Accessing the dictionary: SHA-2 key generator
1.2. Indexing system: localizing the data
1.3. Handling the North Korean KPS 9566 encoding
2. Samhung Multilingual Dictionary (삼흥다국어사전)
2.1. Database loading and protection scheme
2.2. Extracting the data and handling text formatting information
3. Making a dictionary app
3.1. First impressions with Rust
0. Introduction
Dictionaries are an important tool for anyone working with foreign languages. This is particularly more true when dealing with topic-specific vocabulary, for instance when doing research on scientific or technical fields. Unfortunately not many lexical resources are readily available for the North Korean language.
The reference general-purpose dictionary for North Korean is the Great Dictionary of the Korean Langauge (조선말대사전 / chosŏn mal taesajŏn). An online version is available on the North Korean website uriminzokkiri.com but it is extremely slow when available at all. I am fairly certain that Naver’s dictionary used to provide results from this dictionary but this is not the case anymore. Only few offline (digital) resources are available. A github user named takeshixx extracted a SQL database from an English-North Korean dictionary app and made the result available via a Python webapp. This is useful, but the dictionary does not provide the level of detail that a monolingual dictionary provides. And it is of course also not meant to cover technical jargon. A North Korean windows literary/encyclopedia program released in the early 2000’s includes a copy of the dictionary but I was never able to get it to run with Wine on Linux. It’s also quite slow.

On a recent (pre-COVID) trip to North Korea, I was able to purchase a couple of dictionary apps from a local “app store”. The apps are meant to run on a North Korean device equipped with Android 4 but I’d prefer not to have to reach for a tablet and wait for the dictionary app to start every time I need to look up a word. So I figured a solution might be to emulate the work previously done on the English-North Korean dictionary and dump the dictionaries to a more portable file format. Unfortunately each dictionary used a different, custom way to store data and indexes so this proved to be more work than originally envisioned. But in the process, I got to learn about North Korea’s specific encoding (the KPS 9566 / EUC-KP), about using Ghidra with OOP code, and about how North Korean programmers design their databases.
1. Biyak Technoscientific Dictionary (비약과학기술용어사전)
1.1. Accessing the dictionary: SHA-2 key generator
The Biyak dictionary was the one I was the most looking forward to using. Working with North Korean technical papers in electronics, maths and computer science, I often found it challenging to find the definition of some technical jargon. The problem is compounded by the fact that where South Korean scientists would often just use a hangul rendition of an English term, North Korean ones would try to come up with a “native” Korean, or at least Sino-Korean, equivalent (historically at least, North Korean engineers now increasingly opt for simple loanwords). A dictionary published in 1968, the Technoscientific dictionary in 7 languages is a useful resource for those terms, but it’s only available on paper at a few libraries worldwide (none of which are close to me). And since it was published 50 years ago, it’s also a bit outdated when it comes to computer science.
| English | Korean (North) | Korean (South) |
| Database | 자료묶음 (charyo mukkŭm) |
데이터베이스 (deit’ŏ peisŭ) |
| Stack | 탄창 (t’anch’ang) |
스택 (sŭt’aek) |
| Queue | 사슬 (sasŭl) |
큐 (k’yu) |
| Parsing Tree | 도출나무 (toch’ul namu) |
파싱 트리 (p’asing t’ŭri) |
| Path | 길 (kil) |
패스 (p’aesŭ) |
| Unconditional GOTO Statement | 단순건너뛰기명령문 (tansun kŏnnŏ ttwigi myŏngnyŏngmun) |
무조건 GOTO (mujogŏn GOTO) |
Some computer science terms for which South Korean uses an English loanword while North Korean uses Korean or Sino-Korean words. (From 김상옥, 「북한 전자계산학의 소개」, 『정보과학회지』 10(3), 1992)
Unfortunately, the store I purchased it from forgot to activate the licence. This was likely an honest mistake, as I bought a lot of different apps and the man just mass transferred everything to my device. But it still prevented me from accessing an app I had paid for and from examining the dictionary’s content. So the first step before extracting the dictionary’s data was to actually to build a key-generator to be able to access the dictionary.
This, fortunately, was easy enough. After extracting the APK and decompiling the Java code, we find a KrEncryptor class that implements a MatchLicenseKey method:
public class KrEncryptor {
private static byte[][] LicenseCode = {new byte[]{74, 73, 21, 83}, new byte[]{78, 65, 73, 47}, new byte[]{72, 82, 52, 38}};
public static String gKeyNumber = "-1";
public static String g_Barcode;
public static boolean g_isKeyChecked = false;
public static int MatchLicenseKey(String deviceKey, String licenseKey) {
if (licenseKey.length() != 19) {
return -2;
}
byte[] byteDeviceKey = deviceKey.getBytes();
byte[] byteLicenseKey = licenseKey.getBytes();
int[] nDeviceKey = new int[4];
int[] nLicenseKey = new int[3];
for (int i = 0; i < 4; i++) {
nDeviceKey[i] = ((byteDeviceKey[i * 5] - 48) * 1000) + ((byteDeviceKey[(i * 5) + 1] - 48) * 100) + ((byteDeviceKey[(i * 5) + 2] - 48) * 10) + (byteDeviceKey[(i * 5) + 3] - 48);
}
for (int i2 = 0; i2 < 3; i2++) {
nLicenseKey[i2] = ((byteLicenseKey[i2 * 5] - 48) * 1000) + ((byteLicenseKey[(i2 * 5) + 1] - 48) * 100) + ((byteLicenseKey[(i2 * 5) + 2] - 48) * 10) + (byteLicenseKey[(i2 * 5) + 3] - 48);
}
if (((nLicenseKey[0] + nLicenseKey[1]) + nLicenseKey[2]) % 10000 == ((((nDeviceKey[0] * ((LicenseCode[0][0] + LicenseCode[1][0]) + LicenseCode[2][0])) + (nDeviceKey[1] * ((LicenseCode[0][1] + LicenseCode[1][1]) + LicenseCode[2][1]))) + (nDeviceKey[2] * ((LicenseCode[0][2] + LicenseCode[1][2]) + LicenseCode[2][2]))) + (nDeviceKey[3] * ((LicenseCode[0][3] + LicenseCode[1][3]) + LicenseCode[2][3]))) % 10000) {
return -1;
}
if (Global.eckNative.IVerifyKey(deviceKey.replace("-", ""), licenseKey.replace("-", "")) >= 60) {
return 1;
}
return -1;
}
We can tell by looking at where the method is called that what we want is a return value of 1:
public void performOK() {
String strKey = this.authorizedKeyInputBox.getText().toString().replace("-", "-").replace("—", "-");
int res = KrEncryptor.MatchLicenseKey(this.deviceKey, strKey);
if (res == 1) {
KrEncryptor.g_isKeyChecked = true;
KrEncryptor.gKeyNumber = strKey;
try {
KrEncryptor.saveKey(this);
startActivity(new Intent(this, LogoActivity.class));
finish();
} catch (Exception e) {
e.printStackTrace();
}
} else if (res == -1) {
KrEncryptor.g_isKeyChecked = false;
KrEncryptor.alert(this, "허가번호가 틀립니다! ");
} else if (res == -2) {
KrEncryptor.g_isKeyChecked = false;
KrEncryptor.alert(this, "허가번호를 정확하게 입력하십시오! ");
}
}
So the only bit that is of interest to us is the following line:
if (Global.eckNative.IVerifyKey(deviceKey.replace("-", ""), licenseKey.replace("-", "")) >= 60)
Which removes dashes from the deviceKey variable (a unique identifier generated based, among other, on the device’s serial number) and the licenseKey variable (the code we entered) before calling the IVerifyKey() function to verify that the licenseKey entered is valid for the current deviceKey. IVerifyKey(), however, is not implemented in the Java code but in an external library, libeckdata.so which we can analyze using Ghidra.
The code of the IVerifyKey() itself is mostly memory management to copy the strings of the entered license key and the device key before calling a VerifyLicense() function with the two strings and the integer 8 as arguments:
VerifyLicense(req_key,entered_serial,8);
Looking inside the function, the Ghidra decompiling does a decent job of providing a pseudo-C version of the ARM assembly:
int VerifyLicense(char *req_key,char *entered_serial,int xor_value)
{
char cVar1;
tm *ptVar2;
int iVar3;
void *__s;
size_t __n;
int iVar4;
char extraout_r1;
uint uVar5;
time_t tStack324;
byte sha2_hash [256];
undefined4 local_40;
undefined4 local_3c;
undefined4 local_38;
undefined4 local_34;
undefined local_30;
int local_2c;
local_2c = __stack_chk_guard;
time(&tStack324);
ptVar2 = localtim ptVar2 = localtim
iVar3 = ptVar2->tm_sec;
memset(sha2_hash,0,0x100);
local_30 = 0;
local_40 = 0;
local_3c = 0;
local_38 = 0;
local_34 = 0;
__s = malloc(0x40);
memset(__s,0,0x40);
__n = strlen(req_key);
memcpy(__s,req_key,__n);
iVar4 = sha2(sha2_hash,0x100,__s,0x40);
if (iVar4 == 0) {
iVar4 = 0;
do {
while( true ) {
__aeabi_idivmod((int)(char)(sha2_hash[iVar4] ^ (byte)xor_value),10);
uVar5 = (int)extraout_r1 >> 0x1f;
uVar5 = (int)extraout_r1 + uVar5 ^ uVar5;
cVar1 = (char)uVar5;
if ((int)uVar5 < 10) break;
*(char *)((int)&local_40 + iVar4) = cVar1 + '7';
iVar4 = iVar4 + 1;
if (iVar4 == 0x10) goto LAB_00017dde;
}
*(char *)((int)&local_40 + iVar4) = cVar1 + '0';
iVar4 = iVar4 + 1;
} while (iVar4 != 0x10);
LAB_00017dde:
iVar4 = strcmp((char *)&local_40,entered_serial);
if (iVar4 == 0) {
iVar3 = iVar3 + 0x3c;
isVerified = 1;
}
}
free(__s);
if (local_2c == __stack_chk_guard) {
return iVar3;
}
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
So the value of deviceKey is hashed using SHA2, a few basic operations – including xoring with the integer earlier passed as a third argument – are done on the hash to eventually generate a 16 character long numeric string that will be compared with the entered licenseKey. With only some minor hand tweaking, we can reuse the decompiled code to create a working key generator in C. The only other thing we have to watch out for is the format of the output serial which should be 19 character long (or the MatchLicenseKey() method will return -1), which we can do by adding three dashes to separate our 16 digits into 4 groups.
#include <stdio.h>
#include <string.h>
#include "crypto/sha2.h"
int main()
{
char sha2_hash[256];
char req_num[19];
char valid_serial[40];
char formatted_serial[40];
char _s[40];
int _n;
int iVar4;
unsigned int uVar5;
char cVar1;
int xor_value;
int extraout_r1;
printf("Keygenerator for Biyak dictionary\n");
while (strlen(req_num) < 1) {
printf("Device ID Key (At least 1 character, no spaces): ");
scanf("%s", req_num);
}
memset(sha2_hash,0,0x100);
memset(_s,0,0x40);
memset(valid_serial,0,0x40);
memset(formatted_serial,0,0x40);
xor_value = 8;
_n = strlen(req_num);
memcpy(_s, req_num, _n);
iVar4 = sha2(sha2_hash, 0x100, _s, 0x40);
if (iVar4 == 0) {
iVar4 = 0;
do {
while( 1 ) {
extraout_r1 = (int)(char)(sha2_hash[iVar4] ^ xor_value) % 10;
uVar5 = extraout_r1 >> 0x1f;
uVar5 = (extraout_r1 + uVar5) ^ uVar5;
cVar1 = (char)uVar5;
if ((int)uVar5 < 10) break;
valid_serial[iVar4] = cVar1 + '7';
iVar4 = iVar4 + 1;
if (iVar4 == 0x10) goto LAB_00017dde;
}
valid_serial[iVar4] = cVar1 + '0';
iVar4 = iVar4 + 1;
} while (iVar4 != 0x10);
LAB_00017dde:
iVar4 = 0;
for (int i=0; i<0x10; i++) {
if ((i > 0) & (i % 4 == 0)) {
formatted_serial[i+iVar4] = '-';
iVar4++;
}
formatted_serial[i+iVar4] = valid_serial[i];
}
printf("%s\n", formatted_serial);
return 0;
}
}
Using the key generator, we can now validate the license and access the dictionary.
1.2. Indexing system: localizing the data
Looking at the dictionary’s content, what is offered is a substantive and up-to-date trilingual (English, Chinese, Korean) dictionary for a variety of technical fields, ranging from economics to petroleum engineering and computer science. This is indeed interesting (to me) and worth further investigating to try and extract the data.
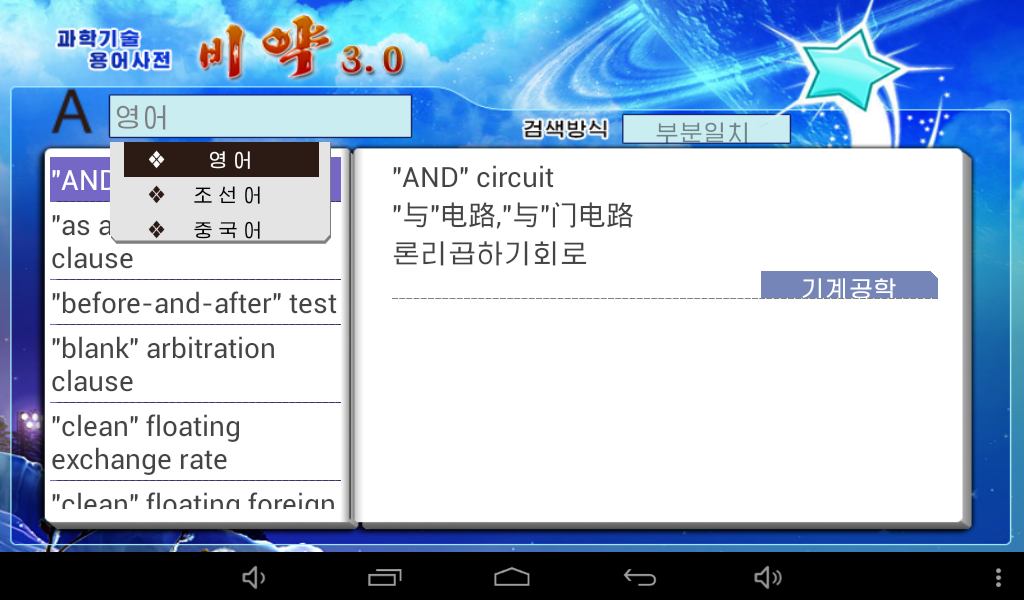
The data is stored in separate file named eckdata.dic that is 395MiB large. Opening it with an hex-editor and browsing through rapidly, we can see a list of English words:
Looking around the Java disassembly is not very fruitful: the Java code mostly handles the GUI but all of the data handling happens in the same library where the licensing code was located.
package com.ciast.biyak;
public class EckNative {
public native void IGetContent(int i, EckContent eckContent);
public native int IGetContentCount(int i);
public native String IGetListWord(int i);
public native String[] IGetListWords(int i, int i2);
public native int IInit(String str);
public native void ISetLanguage(int i);
public native int ISetSearchData(String str, int i);
public native int IVerifyKey(String str, String str2);
static {
System.loadLibrary("eckdata");
}
}
We also get a sense of how the data might be structured, divided between English, Chinese, Korean and the information field giving the technical domain of the word (displayed at the bottom of every definition in a small box with a blue background):
package com.ciast.biyak;
public class EckContent {
String szChinese;
String szEnglish;
String szKorean;
String szSection;
}
So we have to fire up Ghidra again and look at those functions. IGetContent seems like a good place to start since the function’s signature seems to indicate that for a specific index number it returns the corresponding three equivalent terms in English, Chinese and Korean as well their field.
The IGetContent function actually starts with a call to another function GetEckDat that handles the data retrieving process:
/* EckDataSearch::GetEckDat(int) */
undefined4 __thiscall GetEckDat(EckDataSearch *this,int param_1)
{
undefined4 uVar1;
size_t sVar2;
void *pvVar3;
uint uVar4;
XFile *this_00;
char *__s;
char *__s_00;
uVar1 = 0;
if (param_1 < *(int *)(this + 0x28)) {
this_00 = (XFile *)(this + 0x900);
Seek(this_00,param_1 * 4 + *(int *)(this + 0x908),0);
Read(this_00,this + 0x8f8,4);
Seek(this_00,*(int *)(this + 0x908) + *(int *)(this + 0x8f8),0);
Read(this_00,this + 0x8fc,2);
uVar4 = (uint)*(ushort *)(this + 0x8fc);
if (*(int *)(this + 0x920) < (int)uVar4) {
free(*(void **)(this + 0x91c));
*(uint *)(this + 0x920) = (uint)*(ushort *)(this + 0x8fc);
pvVar3 = malloc((uint)*(ushort *)(this + 0x8fc) + 10);
*(void **)(this + 0x91c) = pvVar3;
uVar4 = (uint)*(ushort *)(this + 0x8fc);
}
else {
pvVar3 = *(void **)(this + 0x91c);
}
Read(this_00,pvVar3,uVar4);
*(undefined *)(*(int *)(this + 0x91c) + (uint)*(ushort *)(this + 0x8fc)) = 0;
__s = *(char **)(this + 0x91c);
*(char **)(this + 4) = __s;
sVar2 = strlen(__s);
__s_00 = __s + sVar2 + 1;
*(char **)(this + 8) = __s_00;
sVar2 = strlen(__s_00);
__s_00 = __s_00 + sVar2 + 1;
*(char **)(this + 0xc) = __s_00;
sVar2 = strlen(__s_00);
*(char **)(this + 0x10) = __s_00 + sVar2 + 1;
CanvDat(this,__s);
CanvDat(this,*(char **)(this + 8));
CanvDat(this,*(char **)(this + 0xc));
CanvDat(this,*(char **)(this + 0x10));
uVar1 = 1;
}
return uVar1;
}
I hadn’t encountered object oriented code such as this when working with Ghidra before. A way to rename the object’s attributes from hexadecimal indexes to something more readable would have been great to improve the code’s readability, unfortunately there does not seem to be a way to do this as of now. I don’t think it would be possible to implement such a feature through a simple plugin either… I tried using OOAnalyzer but it doesn’t seem like it handles ARM code. So I simply dumped the entirety of the C code and started looking for where properties of the EckDataSearch object referenced here would have had values assigned to them. It turns out most that is done in what looks like a constructor function:
EckDataSearch * __thiscall EckDataSearch(EckDataSearch *this,char *param_1)
{
void *pvVar1;
XFile *this_00;
*(undefined4 *)this = 0x1b578;
EckArray((EckArray *)(this + 0x8ec),1000);
this_00 = (XFile *)(this + 0x900);
XFile(this_00);
passload(this);
Open(this_00,param_1,0);
m_dicfile._4_4_ = *(undefined4 *)(this + 0x904);
Read(this_00,this + 0x908,4);
Seek(this_00,*(int *)(this + 0x908),0);
Read(this_00,this + 0x8f8,4);
*(uint *)(this + 0x28) = *(uint *)(this + 0x8f8) >> 2;
*(undefined4 *)(this + 0x20) = 0xffffffff;
*(undefined4 *)(this + 0x90c) = 0xffffffff;
*(undefined4 *)(this + 0x914) = 0xffffffff;
*(undefined4 *)(this + 0x910) = 0xffffffff;
this[0x92c] = (EckDataSearch)0x0;
*(undefined4 *)(this + 0x920) = 200;
pvVar1 = malloc(0xd2);
*(void **)(this + 0x91c) = pvVar1;
*(undefined4 *)(this + 0x8e8) = 0;
*(undefined4 *)(this + 0x2c) = 0;
return this;
}
So we open our dictionary file and read the first four bytes into this + 0x908, then move the cursor by that many bytes and read the four bytes there into this + 0x8f8. this + 0x28 is equal to this + 0x8f8 divided by 4, so this + 0x8f8 may be the total number of entries and this + 0x28 the number of entries for each data field (Korean, English, Chinese and “Field”). Looking at the hexadecimal representation of eckdata.dic the first four bytes stored into this + 0x908 look like they’re just the length of a header that is not parsed for now.

this + 0x8f8The first part of the code of GetEckDat thus becomes more comprehensible:
/* param_1 is the "index" integer of the word we are looking for
and this first comparison ensures we are not over the maximum
number of entries in the database */
if (param_1 < *(int *)(this + 0x28)) {
/* reading the dictionary file */
this_00 = (XFile *)(this + 0x900);
/* this + 0x908 is the header size, so an offset to skip the
header when reading the dictionary.
param_1 is the index of the word we are looking for
so we will read the 4 byte value stored at that location and
store it in this + 0x8f8
*/
Seek(this_00,param_1 * 4 + *(int *)(this + 0x908),0);
Read(this_00,this + 0x8f8,4);
/* move the cursor by the OFFSET (30) + the address found in the
index with the previous Read()
*/
Seek(this_00,*(int *)(this + 0x908) + *(int *)(this + 0x8f8),0);
/* Read the first 2 bytes at that address
*/
Read(this_00,this + 0x8fc,2);
uVar4 = (uint)*(ushort *)(this + 0x8fc);
So our dictionary file starts with a header (that we do not use here). The header is immediately followed by an index. The first four bytes of the index are both the number of entries in the address of the first value in the index. The index is really just an array of 32 bit addresses. We retrieve the address for the index number of the word we are looking for, add that to the header length and length of the index and we should now (hopefully) be at where the “content” (the english, korean… definitions) is stored.
The first 2 bytes of the data stored at that address are read and used to allocate memory for a buffer that will receive the rest of content read from that address so they likely correspond to the length of the data. The rest of the code seems to confirm this hypothesis:
Read(this_00,pvVar3,uVar4);
*(undefined *)(*(int *)(this + 0x91c) + (uint)*(ushort *)(this + 0x8fc)) = 0;
__s = *(char **)(this + 0x91c);
*(char **)(this + 4) = __s;
sVar2 = strlen(__s);
__s_00 = __s + sVar2 + 1;
*(char **)(this + 8) = __s_00;
sVar2 = strlen(__s_00);
__s_00 = __s_00 + sVar2 + 1;
*(char **)(this + 0xc) = __s_00;
sVar2 = strlen(__s_00);
*(char **)(this + 0x10) = __s_00 + sVar2 + 1;
CanvDat(this,__s);
CanvDat(this,*(char **)(this + 8));
CanvDat(this,*(char **)(this + 0xc));
CanvDat(this,*(char **)(this + 0x10));
The first call to Read() will read the rest of the content at the previous address. This content is then split into four strings which are sent to a function CanvDat. It would be reasonable to assume that the four strings are the four items we are after, namely the data in English, Chinese, Korean and the corresponding “Field”. Eager to validate this theory, I quickly turned back to the dictionary file opened in my hex editor. Manually computing the address of the first entry (index = 0) is trivial: the header is 0x30 bytes long and the value of the four bytes stored at 0x30 is equal to 0x3651B8, so 0x3551E8 is where we want to look at. Unfortunately things there do not quite look the way I had hoped they would:

If we consider the first two bytes (0x4D) as the length of the following string of characters, we are indeed left with four separate sequences of text separated by a null byte. So we are at the right place but the data looks like it is encrypted… If that is the case, then maybe CanvDat, the last function used in GetEckDat on all four strings, will contain the decryption algorithm:
char * __thiscall CanvDat(EckDataSearch *this,char *param_1)
{
size_t sVar1;
size_t sVar2;
sVar1 = strlen(param_1);
if (0 < (int)sVar1) {
sVar2 = 0;
do {
param_1[sVar2] = (char)*(undefined4 *)(this + ((uint)(byte)param_1[sVar2] + 0x136) * 4);
sVar2 = sVar2 + 1;
} while (sVar1 != sVar2);
}
return param_1;
}
So the decryption algorithm is straightforward enough, but the decryption itself is not easy. On one hand there is nothing more here than a basic substitution cipher (assuming it is indeed a cipher and not just an encoding format). We can confirm this by looking at the lengths of the sequences we found in the hexadecimal editor. They’re 33, 16, 18 and 8 byte long respectively. Now, the first entry in the dictionary is “activity on-node” representation which is 33 character long. The Korean translation is 중심점표시업무활동 which is 9 characters long, so, assuming a 2 byte encoding system, 18 bytes. The field is 경제관리 so likewise 8 bytes for 4 characters. The Chinese translation is 8 characters long, so 16 bytes. We can also verify that the same characters (such as “i”) are encoded the same way (0x37).
On the other hand I could not think of any ways of retrieving the substitution table which seems to be embedded within the EckDataSearch. Assuming that the substitution table starts at 0 we might find a reference to this + 0x4d8 (0x136 * 4) somewhere else in the code where the table is written. The only reference is in a function called passload() called from within the ECKDataSearch constructor function mentioned above:
void __thiscall passload(EckDataSearch *this)
{
int *piVar1;
int *piVar2;
int iVar3;
int iVar4;
int local_80 [4];
undefined4 local_70;
undefined4 local_6c;
undefined4 local_68;
undefined4 local_64;
undefined4 local_60;
undefined4 local_5c;
undefined4 local_58;
undefined4 local_54;
undefined4 local_50;
undefined4 local_4c;
undefined4 local_48;
undefined4 local_44;
undefined4 local_40;
undefined4 local_3c;
undefined4 local_38;
undefined4 local_34;
undefined4 local_30;
undefined4 local_2c;
undefined4 local_28;
undefined4 local_24;
undefined4 local_20;
undefined4 local_1c;
piVar2 = local_80;
local_80[0] = 0;
local_80[1] = 1;
local_80[2] = 10;
local_80[3] = 0x15;
local_70 = 0xe;
local_6c = 0x14;
local_68 = 0x11;
local_64 = 2;
local_60 = 3;
local_5c = 0x10;
local_58 = 5;
local_54 = 0x16;
local_50 = 0x12;
local_4c = 7;
local_48 = 0xf;
local_44 = 0x13;
local_40 = 0xc;
local_3c = 6;
local_38 = 0x17;
local_34 = 0x18;
local_30 = 9;
local_2c = 0xb;
local_28 = 4;
local_24 = 8;
local_20 = 0xd;
local_1c = 0x19;
iVar4 = 0;
do {
piVar1 = (int *)(this + (iVar4 + 0x32) * 4);
iVar3 = 0;
do {
if (iVar4 + iVar3 < 0x100) {
*piVar1 = iVar3 + *piVar2 * 10;
}
iVar3 = iVar3 + 1;
piVar1 = piVar1 + 1;
} while (iVar3 != 10);
iVar4 = iVar4 + 10;
piVar2 = piVar2 + 1;
} while (iVar4 != 0x104);
piVar2 = (int *)(this + 200);
iVar4 = 0;
do {
iVar3 = *piVar2;
piVar2 = piVar2 + 1;
*(int *)(this + ((uint)(iVar3 << 0x18) >> 0x16) + 0x4d8) = iVar4;
iVar4 = iVar4 + 1;
} while (iVar4 != 0x100);
return;
}
Reproducing the function in C and dumping the content of what is written to this is easy. We do get a table that looks like it could be valid candidate:
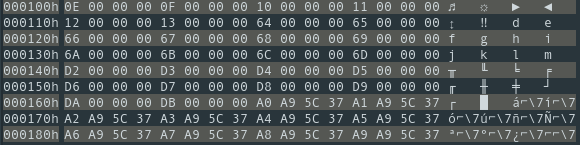
Unfortunately, it does not work. The first character I tried, ", was a match but nothing else matched. And in any case the table generated is way too small to handle Korean and Chinese characters. The decompiled pseudo-C code does not seem to depart from the assembly source either. I can’t quite explain all the unused variables either. Live debugging might be the only way to figure out exactly what the table looks like and how it is generated. Of course, the library does not have debugging information so this will surely be a pain.
There might, however, be a simpler solution. Strangely, the index we just found does not make use of the plain text strings that were spotted earlier while browsing through the file in a hex editor. If we can match those strings, even partially, to those that are encrypted, we could easily derive the substitution table. Of course, we would also need to find a plain text index for Korean strings which we haven’t spotted so far.
The content retrieved from IGetContent which we have looked at up until now is the content that is displayed on the right side of the dictionary (the “content” zone) when a word is selected on the list of words on the left side of the app. Because IGetContent takes an index number as argument, it can not be used to retrieve the list of words in the index. This means that the list of words in the index is retrieved by a different function and potentially from a different part of the data file.
The functions IGetListWords and IGetListWord both are potential suspects here. It turns out that both eventually lead to the same function GetListDat1
undefined4 __thiscall GetListDat1(EckDataSearch *this,int index_of_word)
{
undefined4 uVar1;
size_t sVar2;
void *pvVar3;
uint uVar4;
XFile *this_00;
char *__s;
uVar1 = 0;
if (index_of_word < *(int *)(this + 0x24)) {
this_00 = (XFile *)(this + 0x900);
Seek(this_00,index_of_word * 4 + *(int *)(this + 0x90c),0);
Read(this_00,this + 0x8f8,4);
Seek(this_00,*(int *)(this + 0x90c) + *(int *)(this + 0x8f8),0);
Read(this_00,this + 0x18,1);
uVar4 = (uint)(byte)this[0x18];
if (*(int *)(this + 0x920) < (int)uVar4) {
free(*(void **)(this + 0x91c));
*(uint *)(this + 0x920) = (uint)(byte)this[0x18];
pvVar3 = malloc((uint)(byte)this[0x18] + 10);
*(void **)(this + 0x91c) = pvVar3;
uVar4 = (uint)(byte)this[0x18];
}
else {
pvVar3 = *(void **)(this + 0x91c);
}
Read(this_00,pvVar3,uVar4);
*(undefined *)(*(int *)(this + 0x91c) + (uint)(byte)this[0x18]) = 0;
__s = *(char **)(this + 0x91c);
*(char **)(this + 0x14) = __s;
sVar2 = strlen(__s);
*(char **)(this + 0x1c) = __s + sVar2 + 1;
sVar2 = strlen(__s);
uVar1 = 1;
this[0x18] = SUB41((~sVar2 + (uint)(byte)this[0x18]) * 0x1000000 >> 0x1a,0);
}
return uVar1;
}
This code is very similar to the one we saw earlier, but the properties of EckDataSearch that are being used are different, so we once again have to dive into the full decompiled code to find where their values were assigned. Of particular interest here is the value of this + 0x90c which seems to contain an index. We find a reference to it in a function that handles setting the application’s language:
void __thiscall SetLang(EckDataSearch *this,int param_1)
{
undefined4 uVar1;
EckDataTree *this_00;
int iVar2;
XFile *this_01;
int local_24;
if (*(int *)(this + 0x20) == param_1) {
return;
}
*(int *)(this + 0x20) = param_1;
RemoveAll((EckArray *)(this + 0x8ec));
if (*(int **)(this + 0x8e8) != (int *)0x0) {
(**(code **)(**(int **)(this + 0x8e8) + 4))();
}
this[0x92c] = (EckDataSearch)0x0;
*(undefined4 *)(this + 0x8e8) = 0;
iVar2 = *(int *)(this + 0x20);
if (iVar2 == 4) {
this_01 = (XFile *)(this + 0x900);
Seek(this_01,0x10,0);
Read(this_01,this + 0x90c,4);
Read(this_01,this + 0x910,4);
Read(this_01,this + 0x914,4);
Read(this_01,&local_24,4);
iVar2 = *(int *)(this + 0x914);
}
else {
if (iVar2 != 6) {
if (iVar2 != 0) {
return;
}
this_01 = (XFile *)(this + 0x900);
Seek(this_01,4,0);
Read(this_01,this + 0x90c,4);
Read(this_01,this + 0x910,4);
Read(this_01,this + 0x914,4);
Read(this_01,&local_24,4);
uVar1 = __divsi3(local_24 - *(int *)(this + 0x914),5);
*(undefined4 *)(this + 0x918) = uVar1;
Seek(this_01,*(int *)(this + 0x90c),0);
Read(this_01,this + 0x8f8,4);
*(uint *)(this + 0x24) = *(uint *)(this + 0x8f8) >> 2;
iVar2 = *(int *)(this + 0x910);
goto LAB_00013874;
}
this_01 = (XFile *)(this + 0x900);
Seek(this_01,0x24,0);
Read(this_01,this + 0x90c,4);
Read(this_01,this + 0x910,4);
Read(this_01,this + 0x914,4);
local_24 = GetLength(this_01);
iVar2 = *(int *)(this + 0x914);
}
uVar1 = __divsi3(local_24 - iVar2,5);
*(undefined4 *)(this + 0x918) = uVar1;
Seek((XFile *)(this + 0x900),*(int *)(this + 0x90c),0);
Read((XFile *)(this + 0x900),this + 0x8f8,4);
*(uint *)(this + 0x24) = *(uint *)(this + 0x8f8) >> 2;
iVar2 = *(int *)(this + 0x910);
LAB_00013874:
Seek((XFile *)(this + 0x900),iVar2,0);
Read((XFile *)(this + 0x900),this + 0x8f8,4);
m_sStaFh = *(undefined4 *)(this + 0x910);
this_00 = (EckDataTree *)operator_new(0x38);
EckDataTree(this_00,*(int *)(this + 0x8f8));
*(EckDataTree **)(this + 0x8e8) = this_00;
return;
}
We here finally see where the header mentioned earlier is used. Depending on the value of param_1, we read 3 different addresses in the header one of which gets assigned to this + 0x90c. The values of param_1 that are tested correspond to the numbers mapped to each language by the dictionary’s Java code:
class Global {
public static final int LS_CHINESE = 4;
public static final int LS_ENGLISH = 0;
public static final int LS_KOREAN = 6;
So for each language selected we have three different dense indexes, this seems quite redundant but why not. Going back to GetListDat1(), we see that the code works very similarly to IGetContent(): we move the file cursor to the address of the index found in the header for the language in focus, we retrieve the address for the word we are looking for from the index, add that to the address of the original index and retrieve the result in a string variable. Assuming we want to retrieve information for the first word (index 0) of the English language (0 for EckDataSearch()), we only have to do add a few values to get to where we had hoped to land earlier:

We notice that the first byte of every string corresponds to their length plus four bytes. The value of those four bytes increases with each word, so it is very likely an ID that might help us map the words here to a position in the encrypted data or to their equivalent in other languages.
We can do the same operation to find the beginning of the Korean language index:
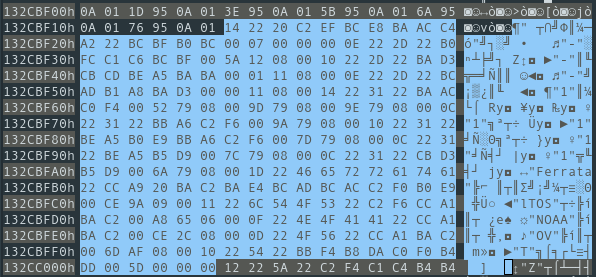
The hexadecimal values however, do not correspond to those of Korean characters in Unicode. It’s unlikely however that the content would be encrypted. The English language word list from earlier was in plain text so there would be little reason to encrypt the Korean one only. Furthermore, we can see pieces of English language words in the hex editor like “Ferrata” which are clearly in plain text and might be part of a word written in mixed latin-hangul script. So rather than encryption we are likely dealing with an encoding issue.
1.3. Handling the North Korean KPS 9566 encoding
Looking for the word “Ferrata” in Biyak dictionary’s Korean mode yields the entry “Ferrata”의 성숙전적혈구, so we can map the byte sequences we have in the hexadecimal editor to the Korean characters they are supposed to represent. I had heard just a few days prior about the KPS 9566 encoding from my good friend fcambus so I decided to check it out. I could not find a program that handled the encoding, but the Unicode consortium provides a text file with mappings. Looking at the entry for 0xCCA9 we find:
0xCCA9 0xC758 #HANGUL SYLLABLE IEUNG YI
with IEUNG YI being the character 의! A nice case of the Baader–Meinhof phenomenon as I had never encountered the encoding before but was now encountering twice in just a few days. Digging around the decompiled code we can actually find a conversion function, however it relies on an unnecessarily large substitution table (all bytes between 0x81 and 0x8141 are empty for instance), so I simply built something based on the substitution table provided by unicode.org. I used it on a dump of the suspected Korean language data after removing the length and indexing info and got a clean Unicode version.
I’m not sure why the developers chose to store the Korean text in this particular encoding rather than Unicode. Especially since they then convert the text to Unicode on the fly every time it is displayed. While it’s only noticeable on special characters, the English text too is actually encoded in KPS 9566. There is a second specific encoding for Chinese too, although I did not look into it. One may also wonder about the amount of redundancy : the same three word lists and their corresponding indexes are stored three times (one for each language), in addition to the encrypted data which largely contains the same information. It’s no wonder that the dictionary file is close to 400MiB.
Anyways, the Korean word list also comes with indexing information, so if we can confirm that this can be matched with the indexing information from the English word list, we could already get the correspondences between the two languages without using the encrypted data. However, the header only contains three indexes per language. This means that the “Field” information (which is always in Korean) is only available in the encrypted content. So we will still have to build a substitution table if we want to get the field information.
I created a simple Python script that handles the dumping of the data from the dictionary file:
class Dumper():
def __init__(self, dicfile):
self.dicfile = open(dicfile, 'rb')
def dump_word_list_as_bytes(self, language_id = 0):
wordlist = {}
lang_index = {0: 0x4, 4: 0x10, 6: 0x24}
if language_id not in lang_index:
self.dicfile.close()
raise ValueError("Invalid Language ID")
self.dicfile.seek(lang_index[language_id])
main_index = Byte4ToInt(self.dicfile.read(4), 0)
self.dicfile.seek(main_index)
max_size = Byte4ToInt(self.dicfile.read(4), 0) >> 2
for i in range(max_size):
self.dicfile.seek(i * 4 + main_index)
cur_word_offset = Byte4ToInt(self.dicfile.read(4), 0)
cur_word_address = main_index + cur_word_offset
self.dicfile.seek(cur_word_address)
word_length = int.from_bytes(self.dicfile.read(1), "little", signed=False)
word, word_index = self.dicfile.read(word_length).split(b'\x00', 1)
word_index = Byte4ToInt(word_index, 0)
wordlist[word_index] = word
return wordlist
def dump_encoded_content(self):
wordlist = []
self.dicfile.seek(0)
header_size = Byte4ToInt(self.dicfile.read(4), 0)
self.dicfile.seek(header_size)
index_size = Byte4ToInt(self.dicfile.read(4), 0)
index_size_per_individual_language = index_size >> 2
for i in range(index_size_per_individual_language):
self.dicfile.seek(header_size + i * 4)
current_word_address = Byte4ToInt(self.dicfile.read(4), 0)
self.dicfile.seek(current_word_address + header_size)
buffer_length = int.from_bytes(self.dicfile.read(2), "little", signed=False)
encoded_content = self.dicfile.read(buffer_length)
szEnglish, szChinese, szKorean, szField, _ = encoded_content.split(b'\x00')
wordlist.append((szEnglish, szChinese, szKorean, szField))
return wordlist
def close(self):
self.dicfile.close()
After dumping the Korean and English word lists as well as the encrypted data, I noticed that the indexes that are given along with the plain text words (in the final four bytes of the word’s string) are very useful. First they make it possible to match words from the two word lists: the English word at index X is the translation of the Korean word at index X and vice versa. They also correspond to an entry in the encrypted data (the Xth element in the list of encrypted data). This is much needed because neither the wordlists nor the encrypted data have the same number of entries (orphan entries maybe?) and so there is no direct 1 to 1 correspondence (the Xth item in the English wordlist could be the Yth item in the Korean wordlist and the Zth entry in the encrypted data with X != Y != Z).
Once we have the data, decryption is simply a matter of matching elements. I’ve only matched the Korean characters since I only need the substitution table for the “Field” data which is in Korean. It also means we don’t have to deal with mixed strings that could have both Latin (1 byte) characters and Korean characters (2 bytes) and just have to worry about matching pairs of bytes. The substitution table produced through this matching allow us to handle all Korean characters from the encrypted data save for a couple that I’ve manually added later.
With the word lists for English and Korean and the decrypted “Field” information all matched, I saved the result to a SQLite database with a very basic schema (see section. 3 below or github).
2. Samhung Multilingual Dictionary (삼흥다국어사전)
The Samhung multilingual dictionary offers bilingual dictionaries for Korean and Chinese/English/French/German/Japanese/Russian as well as a monolingual Korean dictionary which was what I was most interested in. The APK of the Samhung dictionary that was distributed with the Woolim tablet has been made available online. It seems to be the same as the one I purchased last year.

2.1. Database loading and protection scheme
I was hoping for Samhung to follow the same data format as Biyak, but that was not the case (although they do share some similarities). First of all the data is spread out across multiple files. Each dictionary is spread over 4 *.idx and 4 *.sha files.

Opening up these files with a hex editor, it’s not immediately obvious what each is used for, however **Dic.sha files seem to contain some clear text content:
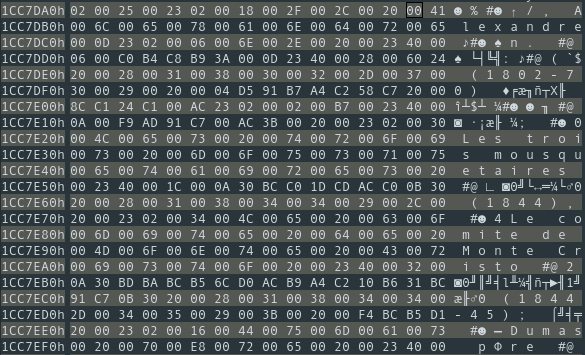
This is not however, a plain text format, and there seems to be quite a lot of noise – or at least bytes whose purpose is not obvious. We don’t really know how to separate the data and link it to a Korean word either, so we will have to look at the code.
Unlike with Biyak, all the code was written directly in Java rather than relying on an external library. The application is also slightly more complex, both in terms of UI and features. But while this increases the amount of code we have to browse through, it will have very little impact on the actual difficulty of extracting the data. Most of the code that is relevant to us is concentrated in the app’s two main classes Samhung which handles the main window and user interaction and BHsearch which handles the data loading and retrieving tasks.
Let’s start by searching for the dictionary files’ name to see where they are loaded. The file names are stored in global variables:
public static final String[] DATA_B_FILE = {"EKKeyB.sha", "KEKeyB.sha", "RKKeyB.sha", "KRKeyB.sha", "CKKeyB.sha", "KCKeyB.sha", "JKKeyB.sha", "KJKeyB.sha", "DKKeyB.sha", "KDKeyB.sha", "FKKeyB.sha", "KFKeyB.sha"};
public static final String[] DATA_D_FILE = {"EKData.sha", "KEData.sha", "RKData.sha", "KRData.sha", "CKData.sha", "KCData.sha", "JKData.sha", "KJData.sha", "DKData.sha", "KDData.sha", "FKData.sha", "KFData.sha"};
public static final String[] DATA_FILE = {"EKDic.sha", "KEDic.sha", "RKDic.sha", "KRDic.sha", "CKDic.sha", "KCDic.sha", "JKDic.sha", "KJDic.sha", "DKDic.sha", "KDDic.sha", "FKDic.sha", "KFDic.sha"};
public static final String[] DATA_M_FILE = {"EKKey.sha", "KEKey.sha", "RKKey.sha", "KRKey.sha", "CKKey.sha", "KCKey.sha", "JKKey.sha", "KJKey.sha", "DKKey.sha", "KDKey.sha", "FKKey.sha", "KFKey.sha"};
public static final int[] FONT_SIZE = {20, 22, 24, 26, 28, 30, 32};
public static final int HELP_STATE = 2;
public static final int HISTORY_STATE = 1;
public static final String[] IDX_B_FILE = {"EKKeyB.idx", "KEKeyB.idx", "RKKeyB.idx", "KRKeyB.idx", "CKKeyB.idx", "KCKeyB.idx", "JKKeyB.idx", "KJKeyB.idx", "DKKeyB.idx", "KDKeyB.idx", "FKKeyB.idx", "KFKeyB.idx"};
public static final String[] IDX_D_FILE = {"EKData.idx", "KEData.idx", "RKData.idx", "KRData.idx", "CKData.idx", "KCData.idx", "JKData.idx", "KJData.idx", "DKData.idx", "KDData.idx", "FKData.idx", "KFData.idx"};
public static final String[] IDX_FILE = {"EKDic.idx", "KEDic.idx", "RKDic.idx", "KRDic.idx", "CKDic.idx", "KCDic.idx", "JKDic.idx", "KJDic.idx", "DKDic.idx", "KDDic.idx", "FKDic.idx", "KFDic.idx"};
public static final String[] IDX_M_FILE = {"EKKey.idx", "KEKey.idx", "RKKey.idx", "KRKey.idx", "CKKey.idx", "KCKey.idx", "JKKey.idx", "KJKey.idx", "DKKey.idx", "KDKey.idx", "FKKey.idx", "KFKey.idx"};
public static final int[] LINE_HEIGHT = {34, 36, 38, 40, 42, 44, 46};
which are then used by a LoadDictionary() function:
public boolean LoadDictionary() {
for (int i = 0; i < 12; i++) {
g_shSearch[i] = new BHSearch();
g_shSearch[i].m_bSecurityType = true;
g_shBSearch[i] = new BHSearch();
g_shBSearch[i].m_bSecurityType = false;
g_shMSearch[i] = new BHSearch();
g_shMSearch[i].m_bSecurityType = false;
g_shDataSearch[i] = new BHSearch();
g_shDataSearch[i].m_bSecurityType = false;
}
g_shHelp = new BHSearch();
g_shHelp.m_bSecurityType = false;
int k = 0;
while (k < 12) {
if (!g_shSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else if (!g_shMSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_M_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_M_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else if (!g_shBSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_M_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_M_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else if (!g_shDataSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_D_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_D_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else {
k++;
}
}
if (g_shHelp.OpenDB(String.valueOf(Global.STR_SYSTEM) + "SKHelp.idx", String.valueOf(Global.STR_SYSTEM) + "SKHelp.sha")) {
return true;
}
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
}
The code instantiates several BHSearch objects to load the database files using the OpenDB)() method. OpenDB)() takes two arguments. Two files that are then stored as this.PosFile and this.DfrFile. If we look at when OpenDB() is called:
if (!g_shSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else if (!g_shMSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_M_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_M_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else if (!g_shBSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_M_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_M_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else if (!g_shDataSearch[k].OpenDB(String.valueOf(Global.STR_SYSTEM) + Global.IDX_D_FILE[k], String.valueOf(Global.STR_SYSTEM) + Global.DATA_D_FILE[k])) {
Toast.makeText(this, R.string.alert_error_readDic, 0).show();
return false;
} else {
k++;
}
We notice that one of the files is an STR_*** file and the other an IDX_ file, which correspond to the .sha and .idx extension repeatedly. So it seems OpenDB() takes a .sha file holding the content we’d like to extract and the corresponding .idx file to handle data retrieval. With the files opened, the method then fills some of the properties of its parent BHSearch object such as the position of the index, its length, etc… It also includes a “security” feature, which is a simple XOR cipher over some of the bytes of the database’s header:
byte[] bytes = new byte[5];
bytes[0] = 0;
util.IntToByte4(nValue, bytes, 1);
if (this.m_bSecurityType) {
int i = 0;
while (i < nLen) {
lpInput[i] = (byte) (lpInput[i] ^ bytes[1]);
int i2 = i + 1;
if (i2 >= nLen) {
break;
}
lpInput[i2] = (byte) (lpInput[i2] ^ bytes[2]);
int i3 = i2 + 1;
if (i3 >= nLen) {
break;
}
lpInput[i3] = (byte) (lpInput[i3] ^ bytes[3]);
int i4 = i3 + 1;
if (i4 >= nLen) {
break;
}
lpInput[i4] = (byte) (lpInput[i4] ^ bytes[4]);
i = i4 + 1;
}
}
util.wmemcpyUni(lpInput, nLen, lpOut);
}
Everything is straightforward enough to be easily reproducible. I went with a Python script and used Android Studio’s live debugging feature to ensure the values extracted by the script were a match:
class BHSearch:
def __init__(self):
self.DfrFile = None
self.PosFile = None
self.bpPBectorQ = bytearray(16)
self.bpPBectorR = bytearray(16)
self.byDfrFileType = 1
self.byPBectorLen = None
self.bySW = 0
self.dwSameKeys = 0
self.dwpKeyList = [0] * BH_2TH_KEYSMAX
self.iDataLen = 0
self.iDataStart = 0
self.iHeaderLen = 0
self.iIndexLen = 0
self.iIndexStart = 0
self.iKeyNumber = 0
self.iKeyPoint = 0
self.iMaxDataSize = 0
self.m_bSecurityType = True
self.nw = [2**i for i in range(15)]
self.cs = [2**i for i in range(8)][::-1]
def OnDBSecurity(self, lpInput, lpOut, nValue, nLen):
secubytes = bytearray(5)
secubytes[0] = 0
IntToByte4(nValue, secubytes, 1)
if self.m_bSecurityType:
i = 0
while i < nLen:
lpInput[i] = lpInput[i] ^ secubytes[1]
i2 = i + 1
if i2 > nLen:
break
lpInput[i2] = lpInput[i2] ^ secubytes[2]
i3 = i2 + 1
if i3 > nLen:
break
lpInput[i3] = lpInput[i3] ^ secubytes[3]
i4 = i3 + 1
if i4 > nLen:
break
lpInput[i4] = lpInput[i4] ^ secubytes[4]
i = i4 + 1
wmemcpyUni(lpInput, nLen, lpOut)
def OpenDB(self, strDBFile1, strDBFile2):
self.PosFile = open(strDBFile1, 'rb')
self.DfrFile = open(strDBFile2, 'rb')
if self.DfrFile is None or self.PosFile is None:
self.PosFile.close()
self.DfrFile.close()
return False
try:
smhgstr = bytearray(300)
Temp = self.DfrFile.read(40)
if Temp.decode() != BH_HEAD_INFO:
self.PosFile.close()
self.DfrFile.close()
return False
Temp = self.DfrFile.read(3)
if Temp[0] != 44:
self.PosFile.close()
self.DfrFile.close()
return False
self.iHeaderLen = Temp[1]
if self.iHeaderLen > 300:
self.PosFile.close()
self.DfrFile.close()
return False
Temp = bytearray(self.DfrFile.read(self.iHeaderLen))
self.OnDBSecurity(Temp, smhgstr, SH_DIC_SERIAL, self.iHeaderLen - 43)
uc = smhgstr[0]
iPos2 = 1
while uc != 56:
if uc == KCGFont_minus_sign:
self.byDfrFileType = smhgstr[iPos2]
iPos = iPos2 + 1
elif uc == 46:
self.bySW = smhgstr[iPos2]
iPos = iPos2 + 1
elif uc == 47:
self.iKeyNumber = Byte4ToInt(smhgstr, iPos2)
iPos = iPos2 + 4
elif uc == 48:
self.iMaxDataSize = Byte4ToInt(smhgstr, iPos2)
iPos = iPos2 + 4
elif uc == 49:
self.byPBectorLen = smhgstr[iPos2]
iPos3 = iPos2 + 1
for i in range(self.byPBectorLen):
self.bpPBectorQ[i] = smhgstr[(i * 2) + iPos3]
self.bpPBectorR[i] = smhgstr[(i * 2) + iPos3 + 1]
iPos = iPos3 + 32
elif uc == 50:
self.iIndexStart = Byte4ToInt(smhgstr, iPos2)
iPos = iPos2 + 4
elif uc == 51:
self.iIndexLen = Byte4ToInt(smhgstr, iPos2)
iPos = iPos2 + 4
elif uc == 52:
self.iDataStart = Byte4ToInt(smhgstr, iPos2)
iPos = iPos2 + 4
elif uc == 53:
self.iDataLen = Byte4ToInt(smhgstr, iPos2)
iPos = iPos2 + 4
else:
self.PosFile.close()
self.DfrFile.close()
return False
uc = smhgstr[iPos]
iPos2 = iPos + 1
self.iKeyPoint = self.iDataStart
return True
except IOError as e:
print(e)
return
def CloseDB(self):
if self.DfrFile is not None:
try:
self.DfrFile.close()
except IOError as e:
print(e)
if self.PosFile is not None:
try:
self.DfrFile.close()
except IOError as e:
print(e)
2.2. Extracting the data and handling text formatting information
Being able to open the various database files and extract what looks like mostly metadata from the decrypted header is nice, but we still have to figure out how the index files and content files are used to retrieve information. Here, we can look into the BHSearch methods to get a better idea of how and where Samhung retrieves the data relevant to us.
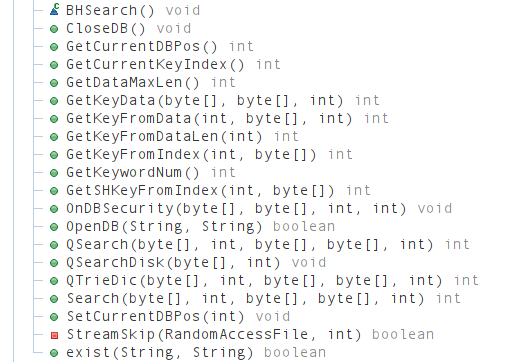
Besides the database handling methods and what looks like full text search methods there are quite few GetKeyxxxx type of methods. Key here might refer to some sort of index or directly to the definition. The signature of GetKeyFromIndex() is particularly interesting because it looks like it takes an integer (index) and a buffer where data will be written. This means we could potentially retrieve all of the data by simply feeding all the indices to this function.
public int GetKeyFromIndex(int nIndex, byte[] lpRealKey) {
if (nIndex < 0 || nIndex >= this.iKeyNumber) {
return -1;
}
try {
StreamSkip(this.PosFile, nIndex * 4);
byte[] str = new byte[4];
this.PosFile.read(str, 0, 4);
this.iKeyPoint = util.Byte4ToInt(str, 0);
} catch (IOException e) {
e.printStackTrace();
}
return GetKeyData(lpRealKey, (byte[]) null, 0);
}
The first conditional statement is good news, because it looks like we are checking whether the entered index (nIndex) falls between 0 and this.iKeyNumber which likely refers to the total amount of values in the index. This means that the nIndex argument is a simple ordinal value. In other words, if we call that function by passing every number between 0 and the total number of words in the dictionary, we might be able to extract all the definitions.
If the value of nIndex is valid, GetKeyFromIndex() will retrieve an address from the index database (PosFile). This is stored as the this.iKeyPoint property. Finally, another method GetKeyData() is called:
public int GetKeyData(byte[] realkey, byte[] attribute, int maxlen) {
byte[] str = new byte[300];
int len = 0;
if (this.DfrFile != null) {
try {
if (!StreamSkip(this.DfrFile, this.iKeyPoint)) {
return -1;
}
if (this.byDfrFileType != 1) {
this.DfrFile.read(str, 0, this.DfrFile.readByte() & 255);
}
int n = this.DfrFile.readByte() & 255;
if (realkey != null) {
this.DfrFile.read(realkey, 0, n);
realkey[n] = 0;
} else {
this.DfrFile.read(str, 0, n);
}
len = n;
if (maxlen > 0) {
this.DfrFile.read(str, 0, 4);
len = util.Byte4ToInt(str, 0);
if (len > maxlen) {
len = maxlen;
}
if (attribute != null) {
this.DfrFile.read(attribute, 0, len);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
return len;
}
The logic here is a bit more convoluted than it may seems. The property this.byDfrFileType is different from 1 for our dictionary files, so we read one byte from the “content” database at the address previously retrieved from the “index” database and stored in this.iKeyPoint. We take the value of that byte and read the file again for as many bytes. The information is not used, but we still have moved the file cursor by a certain number of bytes due to the read operation. We read the the first byte at the new cursor position again and store it in a variable n. We read the file again for n bytes and store this in realkey if the variable exists or in an array str if it doesn’t. realkey is the variable that GetKeyFromIndex() writes to. If realkey is not defined, the value assigned to str is not used.
Then if the maxlen argument has a positive value, we read 4 bytes from the current cursor position and store the value into len, then we read again for len bytes and store that in attribute. Let’s move to the address in question with our hexadecimal editor to get a better sense of what we are reading:
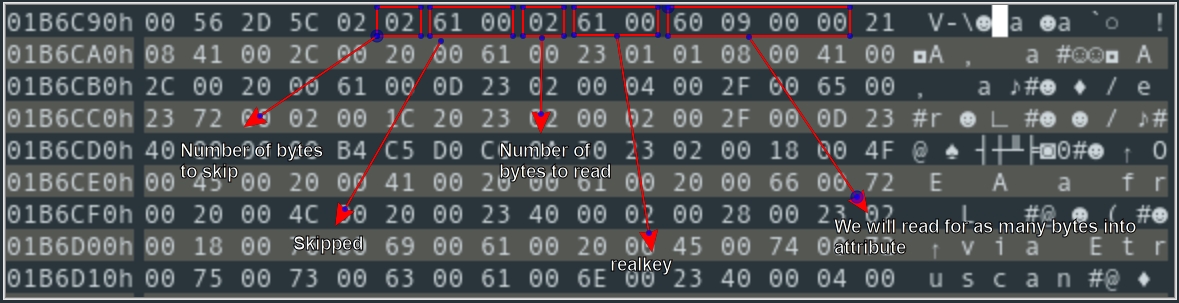
GetKeyData() readsSo it looks like the value of realkey is not what we’re after. But the 4 bytes that are read into len are interesting because if we read for that amount of bytes (0x960) we get something that looks a lot like the first definition we have in the Samhung dictionary for the letter “A”:
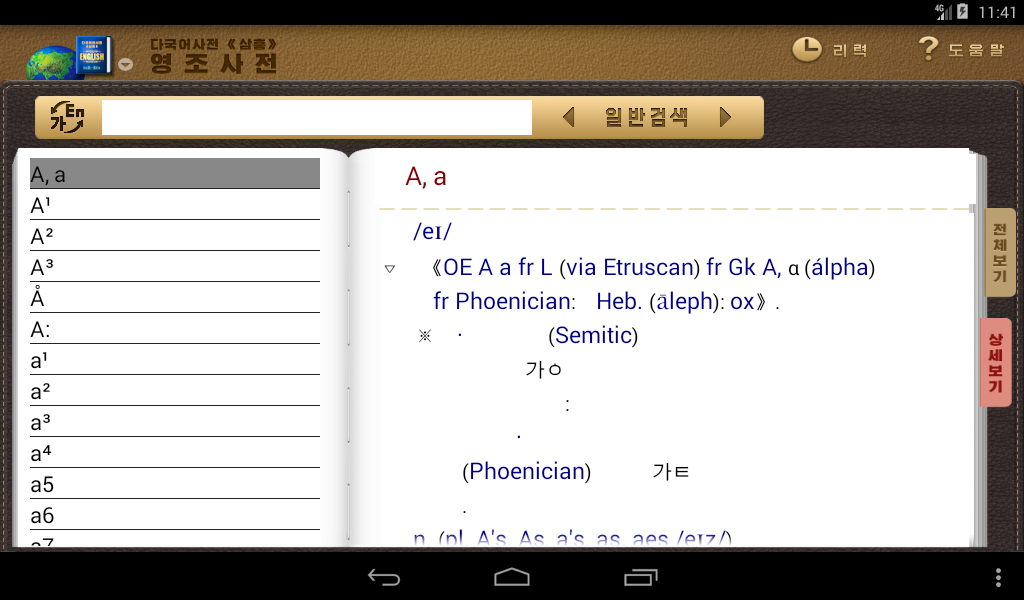
So what we’re interested in is actually the value of attribute. With that understood, we can rewrite the GetKeyData() function to retrieve what we’re after:
def GetKeyData(self):
"""
retrieves the data with the definition/translation
for a specific word from the dictionary db
"""
length = 0
if self.DfrFile is not None:
try:
try:
self.DfrFile.seek(self.iKeyPoint)
except IOError as e:
print(e)
return -1
if self.byDfrFileType != 1:
temp = ord(self.DfrFile.read(1)) & 0xFF
_ = self.DfrFile.read(temp)
n = ord(self.DfrFile.read(1)) & 0xFF
_ = self.DfrFile.read(n)
smhgstr = self.DfrFile.read(4)
length = Byte4ToInt(smhgstr, 0)
attribute = self.DfrFile.read(length)
except Exception as e:
print(e)
return -1
return attribute
We can now retrieve the content from the words in the dictionary. But we’re not done yet! If you look at the text extracted (or the hex editor capture) above, you’ll notice that the text is not quite “plain” text. There are lots of blanks and symbols. Because it’s extremely irregular it looks more like formatting options than an actual encoding issue. So let’s go back to the UX code in the Samhung class to see what happens to the text after it is extracted from the database and before it is displayed.
To display the text data of the definitions, the application uses a CustomView class. This class itself has a SetData() method that the app calls everytime it needs to update the content of CustomView and which in turns calls MakeDrawData() to draw the content:
public boolean MakeDrawData(boolean bInit) {
DeleteSHArrayBuffer();
if (this.m_pbyBuf == null) {
this.m_nLineMax = 0;
return false;
}
byte[] pbyBuf = this.m_pbyBuf;
int[] nDrawWid = {30};
int nDrawWidth = this.VIEW_WIDTH - 30;
int nDataNum = -1;
if (Samhung.m_nCurrentState == 2) {
nDataNum = 0;
}
SHDATA_INFO pDataInfo = new SHDATA_INFO();
pDataInfo.bySpaceNum = 0;
pDataInfo.bPicture = false;
pDataInfo.nPictureID = -1;
SHLINE_INFO pLineInfo = new SHLINE_INFO();
pLineInfo.bySpaceNum = 0;
pLineInfo.bEnd = false;
pLineInfo.nOffset = 0;
pLineInfo.fd = 0.0f;
pLineInfo.mod = 0.0f;
int i = 0;
int nStartPos = 0;
int nLineNum = 0;
int nItemNum = 0;
boolean bFindSpec = false;
while (i < this.m_nBufLen) {
if (pbyBuf[i] == 33) {
int i2 = i + 1;
i = i2 + 1 + (pbyBuf[i2] & 255);
} else if (pbyBuf[i] == 46) {
int i3 = i + 1;
int nLen = util.Byte2ToInt(pbyBuf, i3);
int i4 = i3 + 2;
pLineInfo.bySpaceNum = pDataInfo.bySpaceNum;
pLineInfo.bEnd = false;
pLineInfo.nOffset = 0;
pLineInfo.fd = 0.0f;
pLineInfo.mod = 0.0f;
GetPictureItem(pDataInfo, pbyBuf, i4, nLen);
i = i4 + nLen;
int nPictureLine = (pDataInfo.nPictureHeight / Global.LINE_HEIGHT[Samhung.m_FontSizeNumber]) + 1;
for (int k = 0; k < nPictureLine; k++) {
pDataInfo.ptrSHLineInfo.addElement(pLineInfo);
pLineInfo = new SHLINE_INFO();
pLineInfo.bySpaceNum = 0;
pLineInfo.bEnd = false;
pLineInfo.nOffset = 0;
pLineInfo.fd = 0.0f;
pLineInfo.mod = 0.0f;
}
} else if (pbyBuf[i] == 35 && nDataNum == -1) {
i = i + 5 + util.Byte2ToInt(pbyBuf, i + 3);
} else if (pbyBuf[i] == 35) {
SHITEM_INFO pItemInfo = new SHITEM_INFO();
byte byFace = pbyBuf[i + 1];
pItemInfo.byFaceInfo = byFace;
byte byStyle = pbyBuf[i + 2];
pItemInfo.byStyleInfo = byStyle;
int nDataLen = util.Byte2ToInt(pbyBuf, i + 3);
i += 5;
if (nDataLen > 0) {
while (nDataLen > 0) {
int nCutLen = GetDrawWidth(pItemInfo, pbyBuf, i, nDataLen, nDrawWid, pLineInfo.bySpaceNum, i);
if (nCutLen != 0) {
if (nCutLen <= 0) {
break;
}
pItemInfo.nDataLen = nCutLen;
pItemInfo.nDataPos = i;
pLineInfo.ptrSHItemInfo.addElement(pItemInfo);
int nItemNum2 = nItemNum + 1;
pLineInfo.bEnd = true;
float[] tmpMod = {pLineInfo.mod};
pLineInfo.fd = GetOffsetWidth(pLineInfo, nDrawWidth - pLineInfo.nOffset, pLineInfo.bySpaceNum, tmpMod);
pLineInfo.mod = tmpMod[0];
pDataInfo.ptrSHLineInfo.addElement(pLineInfo);
i += nCutLen;
nLineNum++;
if (nLineNum == 1 && nItemNum2 > 0 && (nStartPos = GetSpecWidth(pLineInfo.ptrSHItemInfo.get(0))) != 0) {
bFindSpec = true;
}
nItemNum = 0;
pItemInfo = new SHITEM_INFO();
pItemInfo.byFaceInfo = byFace;
pItemInfo.byStyleInfo = byStyle;
nDataLen -= nCutLen;
pLineInfo = new SHLINE_INFO();
pLineInfo.bySpaceNum = pDataInfo.bySpaceNum;
pLineInfo.bEnd = false;
pLineInfo.nOffset = 0;
pLineInfo.fd = 0.0f;
pLineInfo.mod = 0.0f;
if (bFindSpec) {
nDrawWid[0] = (pLineInfo.bySpaceNum * Samhung.m_nKoSpaceWidth) + 30 + nStartPos;
pLineInfo.nOffset = nStartPos;
} else {
nDrawWid[0] = (pLineInfo.bySpaceNum * Samhung.m_nKoSpaceWidth) + 30;
pLineInfo.nOffset = 0;
}
} else {
pLineInfo.fd = 0.0f;
pLineInfo.mod = 0.0f;
pDataInfo.ptrSHLineInfo.addElement(pLineInfo);
nLineNum++;
if (nLineNum == 1 && nItemNum > 0 && (nStartPos = GetSpecWidth(pLineInfo.ptrSHItemInfo.get(0))) != 0) {
bFindSpec = true;
}
nItemNum = 0;
pLineInfo = new SHLINE_INFO();
pLineInfo.bySpaceNum = pDataInfo.bySpaceNum;
pLineInfo.bEnd = false;
pLineInfo.nOffset = 0;
pLineInfo.fd = 0.0f;
pLineInfo.mod = 0.0f;
if (bFindSpec) {
nDrawWid[0] = (pLineInfo.bySpaceNum * Samhung.m_nKoSpaceWidth) + 30 + nStartPos;
pLineInfo.nOffset = nStartPos;
} else {
nDrawWid[0] = (pLineInfo.bySpaceNum * Samhung.m_nKoSpaceWidth) + 30;
pLineInfo.nOffset = 0;
}
}
}
if (nDataLen > 0) {
pItemInfo.byFaceInfo = byFace;
pItemInfo.byStyleInfo = byStyle;
pItemInfo.nDataLen = nDataLen;
pItemInfo.nDataPos = i;
pLineInfo.ptrSHItemInfo.addElement(pItemInfo);
nItemNum++;
i += nDataLen;
}
}
} else if (pbyBuf[i] != 13 || nDataNum != -1) {
if (pbyBuf[i] != 13) {
if (pbyBuf[i] != 43) {
break;
}
pDataInfo.bySpaceNum = pbyBuf[i + 1];
pLineInfo.bySpaceNum = pbyBuf[i + 1];
nDrawWid[0] = nDrawWid[0] + (pbyBuf[i + 1] * Samhung.m_nKoSpaceWidth);
i += 2;
} else {
pDataInfo.ptrSHLineInfo.addElement(pLineInfo);
pDataInfo.bMark = false;
int nLineNum2 = nLineNum + 1;
if (bInit) {
this.m_pbyLineState[nDataNum] = true;
this.m_pbyLineShow[nDataNum] = true;
}
this.m_shDataInfo.addElement(pDataInfo);
nDataNum++;
pDataInfo = new SHDATA_INFO();
pDataInfo.bySpaceNum = 0;
pDataInfo.bPicture = false;
pDataInfo.nPictureID = -1;
pLineInfo = new SHLINE_INFO();
pLineInfo.bySpaceNum = 0;
pLineInfo.bEnd = false;
pLineInfo.nOffset = 0;
pLineInfo.fd = 0.0f;
pLineInfo.mod = 0.0f;
i++;
nDrawWid[0] = 30;
bFindSpec = false;
nLineNum = 0;
nItemNum = 0;
nStartPos = 0;
}
} else {
i++;
nDataNum++;
}
}
return true;
}
So the method handles everything to handle the display font, font size and style of each character as well as wordwrap and spacing. The formatting relies on certain “cue” characters to trigger certain actions. These are the characters that we saw seemingly randomly inserted between letters in what otherwise looked like plain text. I don’t really need formatting information to understand a definition so we can remove all of the actual formatting and compile our final string. There is no issue for the most of the text, once we remove things like italics and bold, we end up with an exact copy of the original content in a plain text format. The only problem is with phonetics, however. Samhung gives an IPA phonetic translation of every word in the dictionary. However, for some reason, the application relies on four different True Type fonts to display the phonetic characters.

Note that these are not fonts with support for unicode phonetic symbols but regular fonts where the character for standard ascii codes like 0x41 (A) or 0x42 (B) has been replaced with an unrelated phonetic symbol. This means that creating a mapping between the characters from the fonts and their unicode equivalent would be very time consuming. So let’s forget about phonetics for now.
After finishing the code to handle the formatting, I extracted all data to a SQLite database with the same schema I used for the Biyak dictionary.
3. Making a dictionary app

With the dictionaries dumped in sqlite databases all I needed was a simple app that would allow me to search/browse the dictionaries. I opted for Rust although it may not be the most practical option for this use case. But I had never tried the language before and thought it would be worth trying for a COVID-lockdown weekend project. I also wanted something that I could potentially port to Windows later (although I ended up realizing that a termion-based app definitely wasn’t the smartest choice for that). I used tui-rs for the TUI and rusqlite to handle the DB connection & queries. There’s not much I can say in terms of advice and recommendation with a language I’ve only used for a few days, so instead I’ll just list some first impressions.
3.1. First impressions with Rust
- IDE: The lack of integrated IDE support has been cited as a problem for the language’s adoption. Being familiar with JetBrain IDEs as I use them for other languages, I went with CLion. Setting up was a breeze and the debugging features were more than enough for such a small scale project.
- Learning Curve: This was supposed to be a weekend project, but I ended up spending an entire day just going over the Rust book. New concepts such as borrowing are well explained. Unfortunately such concepts were easy to understand but hard to get used to. Kind of like learning a new grammar form in a foreign language, you may understand how it works and what it means quickly but it can take a lot of time and practice for you to actually use it properly in context. But what I felt was the main obstacle as a newcomer, however, was the “variability” of the language and libraries. For the language itself at least one change that left me bewildered was the switch from
try!()to?, even though the former can still be found in documentation and github code. (And of course googling for information on?is not fun). The various ways of handling errors (try!,?,unwrap,unwrap_or,expect) might be nice, but are also a bit confusing at first. More than the language itself however, were the crates, were it seems like every new version would come with a redesign of its APIs. This make it harder for a newbie to find working examples to study. But even finding information from the documentation can be troublesome: while docs.rs provides great documentation with a full history, version by version, but usually google will have indexed pages from an older version so if this is your point of entry you may spend a couple minutes looking at the doc of a crate only to realize you’re a few versions late and the API has changed entirely. - Community: The enthusiasm, helpfulness and erudition of the few Rust users I interacted with was one of the reasons that I wanted to give the language a try. That first impression was more than vindicated by my first few days asking questions around. I found users to be very supportive and their answers extremely meticulous. (Although some answers did raise more questions than I asked for, but this was always in a good way).
- Usage: Dashing off a basic database query app is clearly not a good way to get Rust to shine and showcase its strengths so I have little to say on the matter, except that I did like how the language constantly nudges you towards cleaner code. At several points compiler errors left me feeling stuck unless I refactored my code. Ownership issues also showed up much more than I would have expected, and getting used to handling them with Rust would certainly transfer to other languages.
- Crates and modules: While I really appreciate Cargo as a dependency manager and the forcing the listing of dependencies’ versions in Cargo.toml. I am still confused by the module system. Hopefully this will get better with practice but it certainly is not intuitive. The fact that crates and modules are in the same namespace also does not help code readability/comprehension for a newcomer, as what comes from where is hard to figure out.
- Binary size:I was surprised by the size of Rust binaries for a GC-free language that is often compared to C and C++. This is however apparently a well known problem with some solutions.
Code source and all the dictionaries converted into SQLite databases are available on github.
The weekend is over, but the lockdown isn’t, so hopefully I’ll have more time to toy around with Rust in the future.